There are many resources available through downloads and APIs. There are, however, cases in which you want to acquire data from the public-facing web. R can be used to access the web programmatically through a process known as web scraping. The complexity of web scrapes can vary but in general it requires more advanced knowledge of R as well as the structure of the language of the web: HTML (Hypertext Markup Language).
HTML: language of the web
HTML is a cousin of XML (eXtensible Markup Language) and as such organizes web documents in a hierarchical format that is read by your browser as you navigate the web. Take for example the toy webpage I created as a demonstration in (fig-example-webpage?).
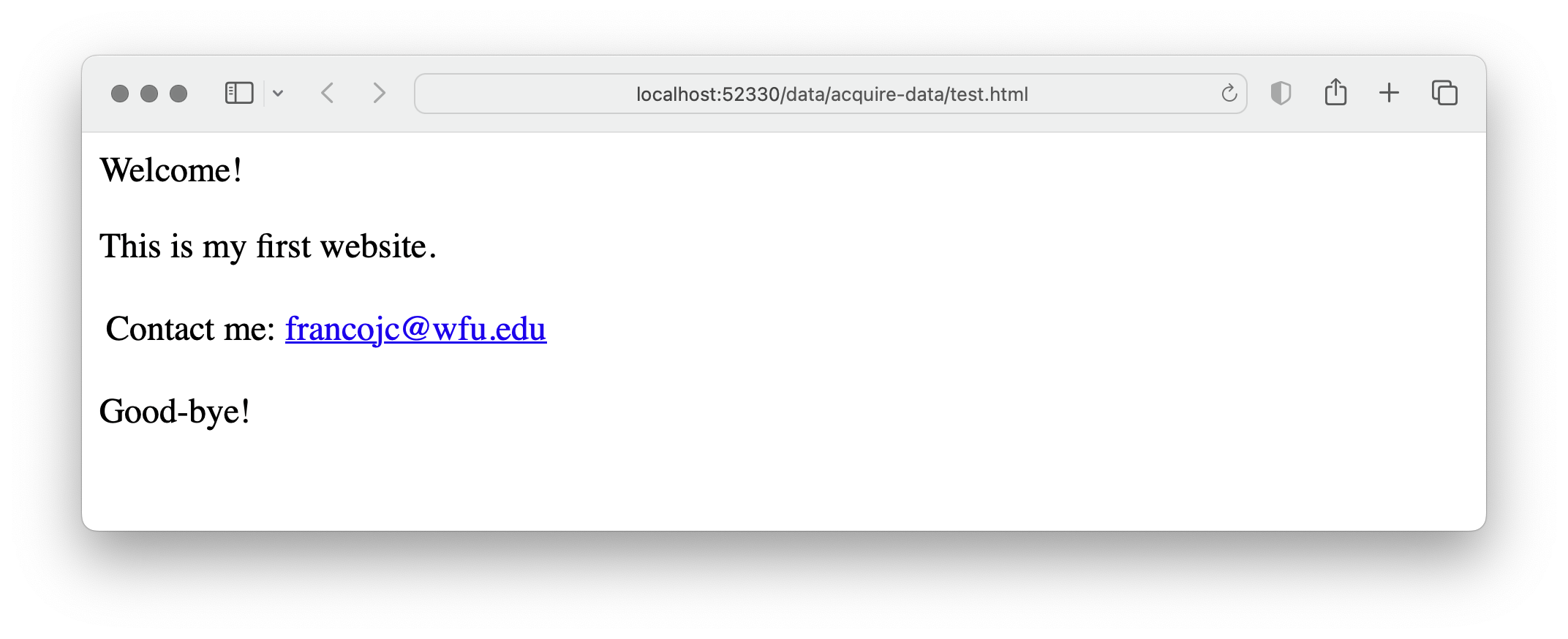
Figure 1: Example web page.
The file accessed by my browser to render this webpage is test.html and in plain-text format as seen in (exm-html-structure?).
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org/TR/REC-html40/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title>My website</title>
</head>
<body>
<div class="intro">
<p>Welcome!</p>
<p>This is my first website.</p>
</div>
<table>
<tr>
<td>Contact me:</td>
<td>
<a href="mailto:francojc@wfu.edu">francojc@wfu.edu</a>
</td>
</tr>
</table>
<div class="conc">
<p>Good-bye!</p>
</div>
</body>
</html>Each element in this file is delineated by an opening and closing HTML tag, <head></head>. Tags are nested within other tags to create the structural hierarchy. Tags can take class and id labels to distinguish them from other tags and often contain other attributes that dictate how the tag is to behave according to Cascading Style Sheet (CSS) rules when rendered visually by a browser. For example, there are two <div> tags in our toy example: one has the label class = "intro" and the other class = "conc". <div> tags are often used to separate sections of a webpage that may require special visual formatting. The <a> tag, on the other hand, creates a web link. As part of this tag's function, it requires the attribute href= and a web protocol --in this case it is a link to an email address mailto:francojc@wfu.edu. More often than not, however, the href= contains a URL (Uniform Resource Locator). A working example might look like this: <a href="https://francojc.github.io/">My homepage</a>.
{{< fa medal >}} Dive deeper
Cascading Style Sheets (CSS) are used to dictate how HTML elements are rendered visually by a browser. For example, the div tag with the class attribute intro could be targeted by a CSS rule to render the text in a larger font size and in bold. CSS rules are often written in a separate file and linked to the HTML file. For web scraping purposes, however, we are not interested in the visual rendering of the HTML file, but rather the structure of the HTML file. These tag attributes can provide useful information for parsing HTML files.
The aim of a web scrape is to download the HTML file(s) that contain the data we are interested in. This will include more information that we may ultimately need, but by downloading the raw source HTML we are effectively creating a local archive, or copy, of the webpage. Thus, if the webpage is updated or removed from the web, we will still have access to the data we accessed.
Later in the curation process we will parse (i.e. read and extract) target information that is relevant for the research at hand. However, it often useful to parse the raw HTML in the process of acquiring data if we are interested in harvesting data from multiple pages and we would like to use the HTML structure to guide our data extraction (i.e. URLs to other pages)
To provide some preliminary background on working with HTML, we will use the toy example above to demonstrate how to read and parse HTML using R. To do this we will use the rvest(Wickham 2022) package. First, install/load the package, then, read and parse the HTML from the character vector named web_file assigning the result to html.
## {html_document}
## <html>
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
## [2] <body>\n <div class="intro">\n <p>Welcome!</p>\n <p>This is ...In (exm-read-html-toy?) read_html() retrieves the raw HTML and it makes it accessible to parsing in R. Being a subtype of XML, read_html() converts the raw HTML into an object of class xml_document, as we can see by calling class() on the html object in (exm-class-html-toy-class?).
## [1] "xml_document" "xml_node"An object of class xml_document represents each HTML tag as a node. The tag nodes are elements can be accessed by using the html_elements() function by specifying the tag/node/element to isolate.
## {xml_nodeset (2)}
## [1] <div class="intro">\n <p>Welcome!</p>\n <p>This is my first web ...
## [2] <div class="conc">\n <p>Good-bye!</p>\n </div>Notice that the output of (exm-parse-html-toy-1?) has returned both div tags and their respective children, tags contained within. To isolate one of tags by its class, we add the class name to the tag separating it with a ..
## {xml_nodeset (1)}
## [1] <div class="intro">\n <p>Welcome!</p>\n <p>This is my first web ...Great. Now say we want to drill down and isolate the subordinate <p> nodes. We can add p to our node filter, as in (exm-parse-html-toy-3?).
## {xml_nodeset (2)}
## [1] <p>Welcome!</p>
## [2] <p>This is my first website.</p>To extract the text contained within a node we use the html_text() function.
## [1] "Welcome!" "This is my first website."The result of (exm-parse-html-toy-4?) is a character vector with two elements corresponding to the text contained in each <p> tag. If you were paying close attention you might have noticed that the second element in our vector includes extra whitespace after the period. To trim leading and trailing whitespace from text we can add the trim = TRUE argument to html_text(), as in (exm-parse-html-toy-5?).
## [1] "Welcome!" "This is my first website."With this basic understanding of how to read and parse HTML, we can now turn to a more realistic example.
Acquire data from the web
Federalist Papers
Say we investigate the authorship question of the the Federalist Papers following in the footsteps of Mosteller and Wallace (1963). We want to scrape the text of the Federalist Papers from the Library of Congress website. The main page for the Federalist Papers is located at https://guides.loc.gov/federalist-papers/full-text and can be seen in (fig-web-scrape-screenshot?).
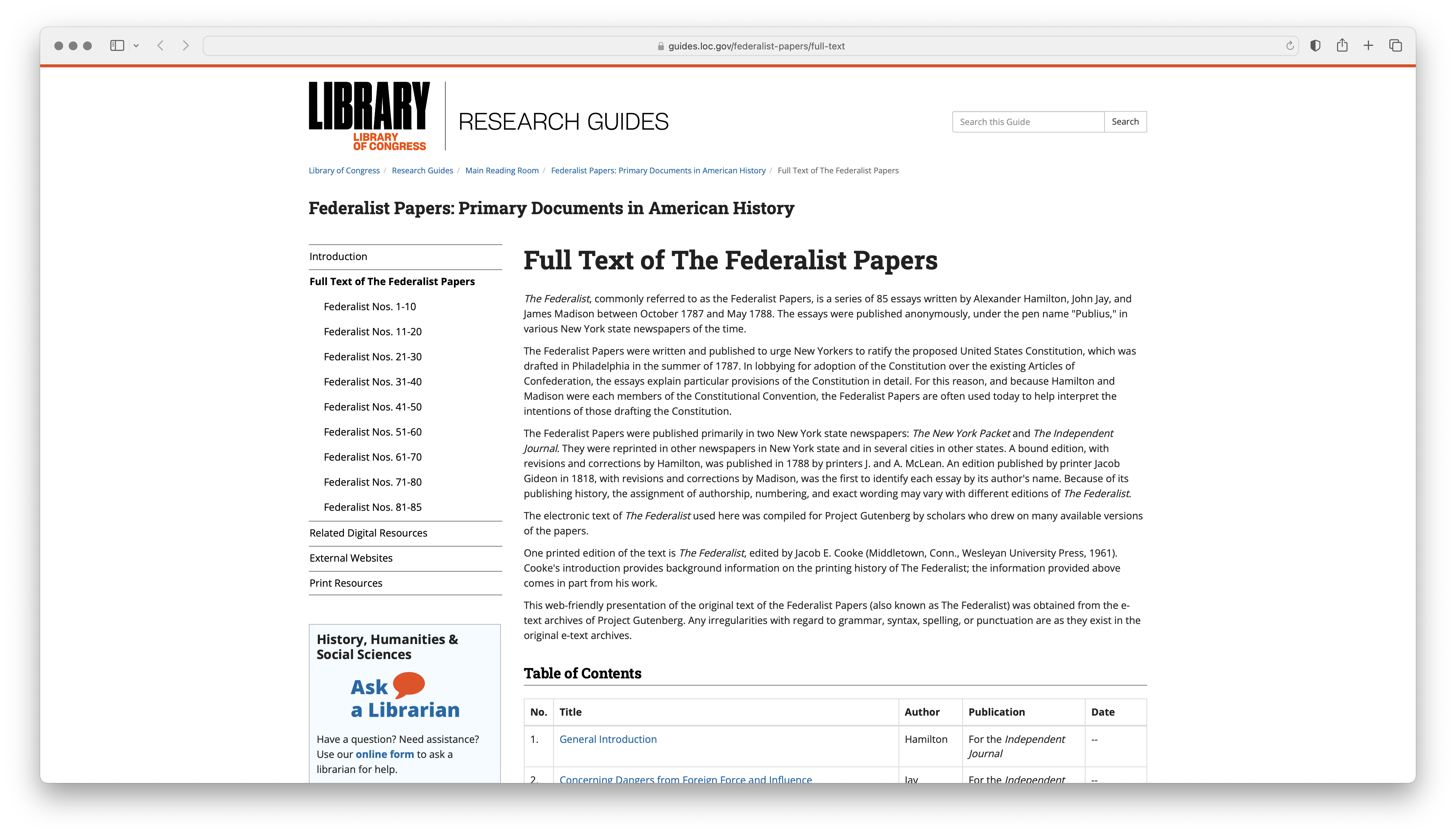
Figure 2: Screenshot of the Library of Congress website for the Federalist Papers
The main page contains links to the text of each of the 85 papers. Our goal will be to scrape and archive the raw HTML for this page and then parse the HTML to extract the links to each of the papers. We will then scrape and archive the raw HTML for each of the 85 papers.
The first step in any web scrape is to investigate the site and page(s) we want to scrape to ascertain if there any licensing restrictions. Many, but not all websites, will include a plain text file robots.txt at the root of the main URL. This file is declares which webpages a 'robot' (including web scraping scripts) can and cannot access. We can use the robotstxt package to find out which URLs are accessible 1.
## [1] TRUEThe next step is to read and parse the raw HTML. We can do this using the read_html() function.
## {html_document}
## <html lang="en">
## [1] <head>\n<meta http-equiv="X-UA-Compatible" content="IE=Edge">\n<meta http ...
## [2] <body class="s-lg-guide-body">\r\n<a id="s-lg-public-skiplink" class="ale ...At this point we have captured the raw HTML assigning it to the object named html. Let's archive the raw HTML to a file in our project directory. We can do this using the write_html() function from the xml2 package (R-xml2?).
Our update project directory structure can be seen in (exm-fed-project-dir?).
Now, we also want to scrape the HTML that contains of the pages corresponding to the 85 Federalist Papers. Perusing the main page we can see that papers are organized into nine groups, e.g. "Federalist Nos. 1-10". So our aim will be to scrape the HTML for each of these nine pages. We can do this using the rvest package, but we need to identify the HTML elements that contain the URLs first in the main webpage we have in html.
To do this it is helpful to use a browser to inspect specific elements of the webpage, much as we did in the toy example in (exm-html-structure?). To view the raw and displayed HTML, your browser will be equipped with a command that you can enable by hovering your mouse over the element of the page you want to target and using a right click to select "Inspect" (Chrome) or "Inspect Element" (Safari, Brave). This will split your browser window vertical or horizontally showing you the displayed and raw HTML underlying the webpage.
We can see the HTML elements that contain the URLs in (fig-fed-inspect?).
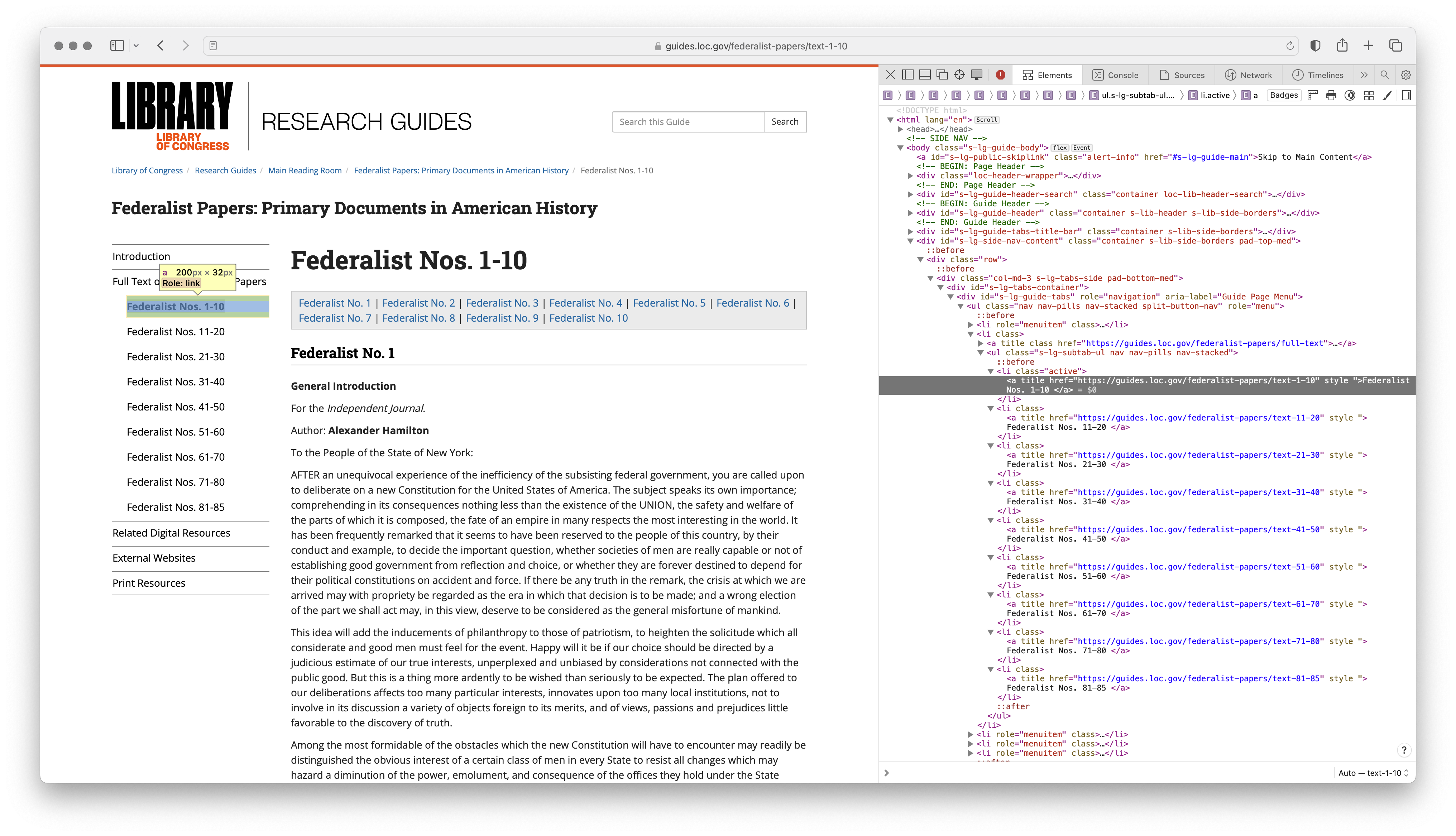
Figure 3: Screenshot of the HTML elements containing the URLs for the Federalist Papers
Let's take a closer look at the source HTML in (fig-fed-inspect-source?) so we can inspect the elements that contain the URLs and divise a strategy for isolating them to be extracted.
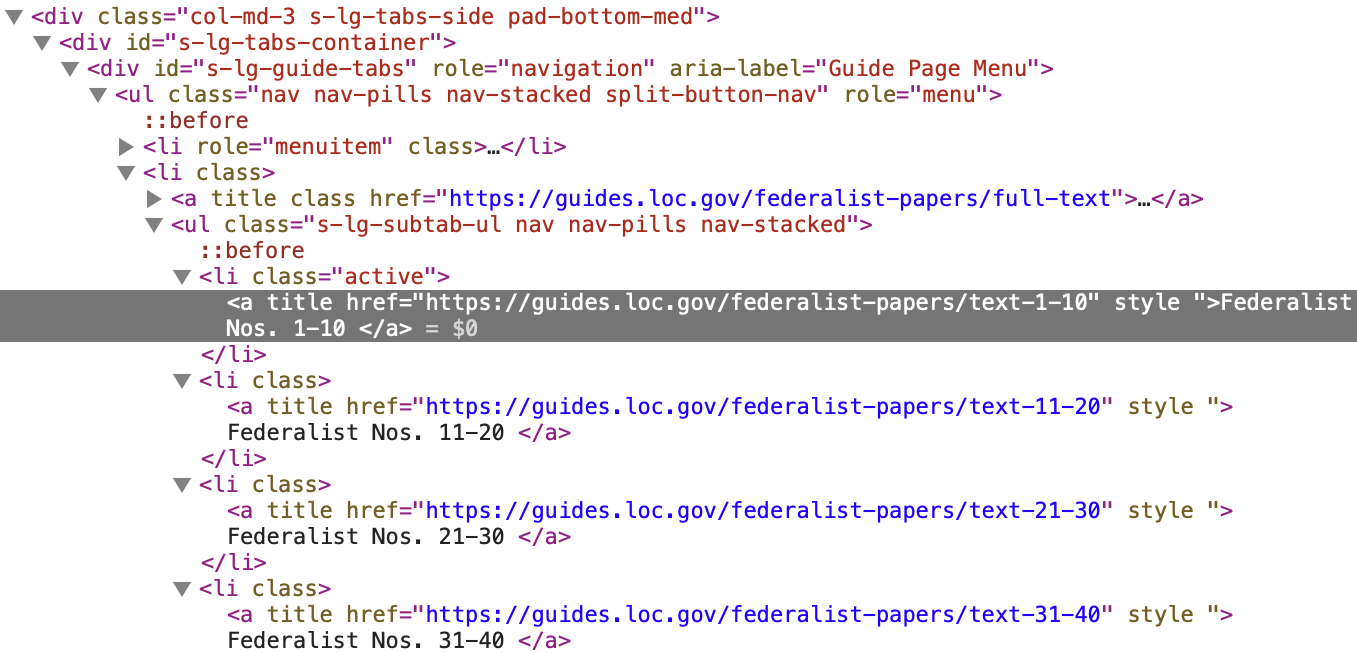
Figure 4: Screenshot of the source HTML for the Federalist Papers
In (fig-fed-inspect-source?) we can see that the HTML elements that contain the URLs are nested within a <ul> element. The <ul> element has a set of class attributes (.s-lg-subtab-ul, nav, nav-pills, nav-stacked). If one of these is unique to this <ul> element we can use it to isolate the element. Let's search the HTML for all the <ul> elements on the page.
## {xml_nodeset (4)}
## [1] <ul class="nav nav-pills nav-stacked split-button-nav" role="menu">\n<li ...
## [2] <ul class="s-lg-subtab-ul nav nav-pills nav-stacked">\n<li class=""><a ti ...
## [3] <ul id="s-lg-page-prevnext" class="pager s-lib-hide">\n<li class="previou ...
## [4] <ul id="s-lg-guide-header-attributes" class="">\n<li id="s-lg-guide-heade ...The output from (exm-fed-papers-loc-url-ul?) shows that there are 4 <ul> elements on the page. It's a little hard to see in the output, but the second <ul> element is the one we are targeting, as it contains the class attributes we identified in (fig-fed-inspect-source?). We can use the html_attr() function to extract the class attribute from the <ul> elements to see if one of them is unique to the <ul> element we want to isolate.
## [1] "nav nav-pills nav-stacked split-button-nav"
## [2] "s-lg-subtab-ul nav nav-pills nav-stacked"
## [3] "pager s-lib-hide"
## [4] ""Effectively this is the case, as the second <ul> element in the output of (exm-fed-papers-loc-url-ul-class?) has a unique class attribute, .s-lg-subtab-ul. We can use this to isolate the element using the html_nodes() function. We then pipe this to another html_nodes() function to isolate the <li> elements nested within the <ul> element. See (exm-fed-papers-loc-url-ul-class-s-lg-subtab-ul?).
## {xml_nodeset (9)}
## [1] <li class=""><a title="" href="https://guides.loc.gov/federalist-papers/t ...
## [2] <li class=""><a title="" href="https://guides.loc.gov/federalist-papers/t ...
## [3] <li class=""><a title="" href="https://guides.loc.gov/federalist-papers/t ...
## [4] <li class=""><a title="" href="https://guides.loc.gov/federalist-papers/t ...
## [5] <li class=""><a title="" href="https://guides.loc.gov/federalist-papers/t ...
## [6] <li class=""><a title="" href="https://guides.loc.gov/federalist-papers/t ...
## [7] <li class=""><a title="" href="https://guides.loc.gov/federalist-papers/t ...
## [8] <li class=""><a title="" href="https://guides.loc.gov/federalist-papers/t ...
## [9] <li class=""><a title="" href="https://guides.loc.gov/federalist-papers/t ...Great. Now, to get the URLs we add another html_nodes() function to (exm-fed-papers-loc-url-ul-class-s-lg-subtab-ul?) to isolate the <a> elements nested within the <li> elements and then a function html_attr() to extract the value of an attribute. In this case, the attribute of the <a> elements we want is href. See (exm-fed-papers-loc-url-ul-li-a?).
## [1] "https://guides.loc.gov/federalist-papers/text-1-10"
## [2] "https://guides.loc.gov/federalist-papers/text-11-20"
## [3] "https://guides.loc.gov/federalist-papers/text-21-30"
## [4] "https://guides.loc.gov/federalist-papers/text-31-40"
## [5] "https://guides.loc.gov/federalist-papers/text-41-50"
## [6] "https://guides.loc.gov/federalist-papers/text-51-60"
## [7] "https://guides.loc.gov/federalist-papers/text-61-70"
## [8] "https://guides.loc.gov/federalist-papers/text-71-80"
## [9] "https://guides.loc.gov/federalist-papers/text-81-85"We can assign the URLs to a variable, fed_urls.
With the URLs in hand, we can now retrieve the HTML for each of the nine pages. We can, of course, do this manually, as in (exm-fed-papers-rewrite-html-manual?).
But this is tedious and error prone, furthermore, it doesn't scale well. If we had 1000 URLs to retrieve the HTML from, we would have to write 1000 lines of code. Instead, we can write a function to do this for us. See (exm-fed-papers-rewrite-function?).
The function in (exm-fed-papers-rewrite-function?) takes a URL as it's only argument. It then creates a file name and path from the URL. The file name is the last part of the URL, with the extension .html. The file path is the path to the federalist_papers directory in the data/original directory. The function then reads the HTML from the URL and writes it to the file.
(exm-fed-papers-rewrite-function?) might not seem like a step up from (exm-fed-papers-rewrite-html-manual?), but it is. We can now use the walk() function from purrr to iterate over the URLs in fed_urls and apply the read_write_html() function to each URL. See (exm-fed-papers-rewrite-map?).
{{< fa regular hand-point-up >}} Tip
When processing multiple webpages, it's often important to manage the load on the server. In R, we can use the Sys.sleep() to introduce short delays between requests. This helps reduce server load when iterating over a list of webpages.
For example, we can use Sys.sleep(1) in our function to introduce a 1 second delay between requests.
read_write_html <- function(url) {
Sys.sleep(1) # 1 second delay
# ...
}Another tip is to use the message() function to print a status message to the console. This can be helpful when processing a large number of webpages.
The result of (exm-fed-papers-rewrite-map?) can be seen in the project directory in (exm-fed-papers-directory?).
And of course, to finish the acquisition process, we need to ensure we have documented the code and created a data origin file. Since we have created this resource it much of the information will be up to use to document. Keep in mind that the data origin file should be written in a way that is transparent to the researcher and to would-be collaborators and the general research community.
In this section, we have built on previously introduced R coding concepts and employed various others in the process of acquiring data from the web. We have also considered topics that are more general in nature and concern interacting with data found on the internet. As you likely appreciate, web scraping often requires more knowledge of and familiarity with R as well as other web technologies. Rest assured, however, practice will increase confidence in your abilities. I encourage you to practice on your own with other websites.
Curate data
Orientation
To provide an example of the curation process using semi-structured data, we will work with the Federalist Papers data acquired from a web scrape of the Library of Congress website in (sec-acquire-data?). The data is stored in a series of HTML files, as seen in (exm-cd-federalist-data-files?).
Our data origin file, fed_papers_do.csv in (tbl-cd-fed-data-origin?), gives us an overview of the data.
| attribute | description |
|---|---|
| Resource name | The Federalist Papers |
| Data source | https://guides.loc.gov/federalist-papers/full-text, Library of Congress Research Guides |
| Data sampling frame | Full texts of the 85 Federalist Papers as available on the mentioned URL, including all documents authored by Alexander Hamilton, James Madison, and John Jay. |
| Data collection date(s) | Web scrape performed August 9, 2023 |
| Data format | Raw HTML files |
| Data schema | The 85 papers are grouped in 9 HTML files (e.g. text-1-10.html) |
| License | Public Domain |
| Attribution | Research Guides: Federalist Papers: Primary Documents in American History: Introduction. (n.d.). Library of Congress Research Guides. Retrieved August 9, 2023, from https://guides.loc.gov/federalist-papers/introduction |
From the file structure and the data origin description, we can surmise that we are working with HTML files which will contain the 85 Federalist Papers. The 85 papers are grouped into 9 files, meaning that for each file there will be multiple papers contained within. We can also see that the HTML files are named according to the range of papers contained within each file. For example, the text-1-10.html file contains the first 10 papers.
It is also a good idea to inspect the data files themselves. Since these are HTML files, we can open them in a web browser. (fig-cd-federalist-html?) shows the text-1-10.html file opened in a web browser.

Figure 5: The text-1-10.html file opened in a web browser.
At this point we want to think about what our curated dataset will look like in terms of rows and columns. For the columns, it is helpful to think about what variables we can extract from each of the Federalist Papers. For example, we can extract the paper number, the paper title, the paper's author(s), the venue in which the paper was published, and the paper's text. Of these variables, the paper number, title, and author(s) are metadata about the paper, while the venue is metadata about the publication of the paper, so we will leave venue out of our curated dataset.
For the rows, we can think about what the unit of analysis is. If we want to conduct a text analysis of the Federalist Papers to predict the author of the paper based on features of the text, then the unit of analysis will be the paper. Now, we can envision a case in which each row is a paper, but to may be the case that the structure of the papers, namely the paragraphs, could be of some use to us. We will keep this in mind as we work through the curation process.
With this information in mind, an idealized version of our curated dataset is shown in (tbl-cd-fed-data-idealized?).
| number | title | author | text |
|---|---|---|---|
| 1 | ... | ... | ... |
| 2 | ... | ... | ... |
| ... | ... | ... | ... |
| 85 | ... | ... | ... |
Tidy the data
The idealized dataset structure will guide our work. To extract the data and metadata from the files we will need to take a closer look at the structure of the HTML documents. We start with the HTML file we opened in a browser in (fig-cd-federalist-html?) and look at the HTML source code with the browser's inspect tool. (fig-cd-federalist-html-inspect?) shows the HTML source code for the first paper in the text-1-10.html file.
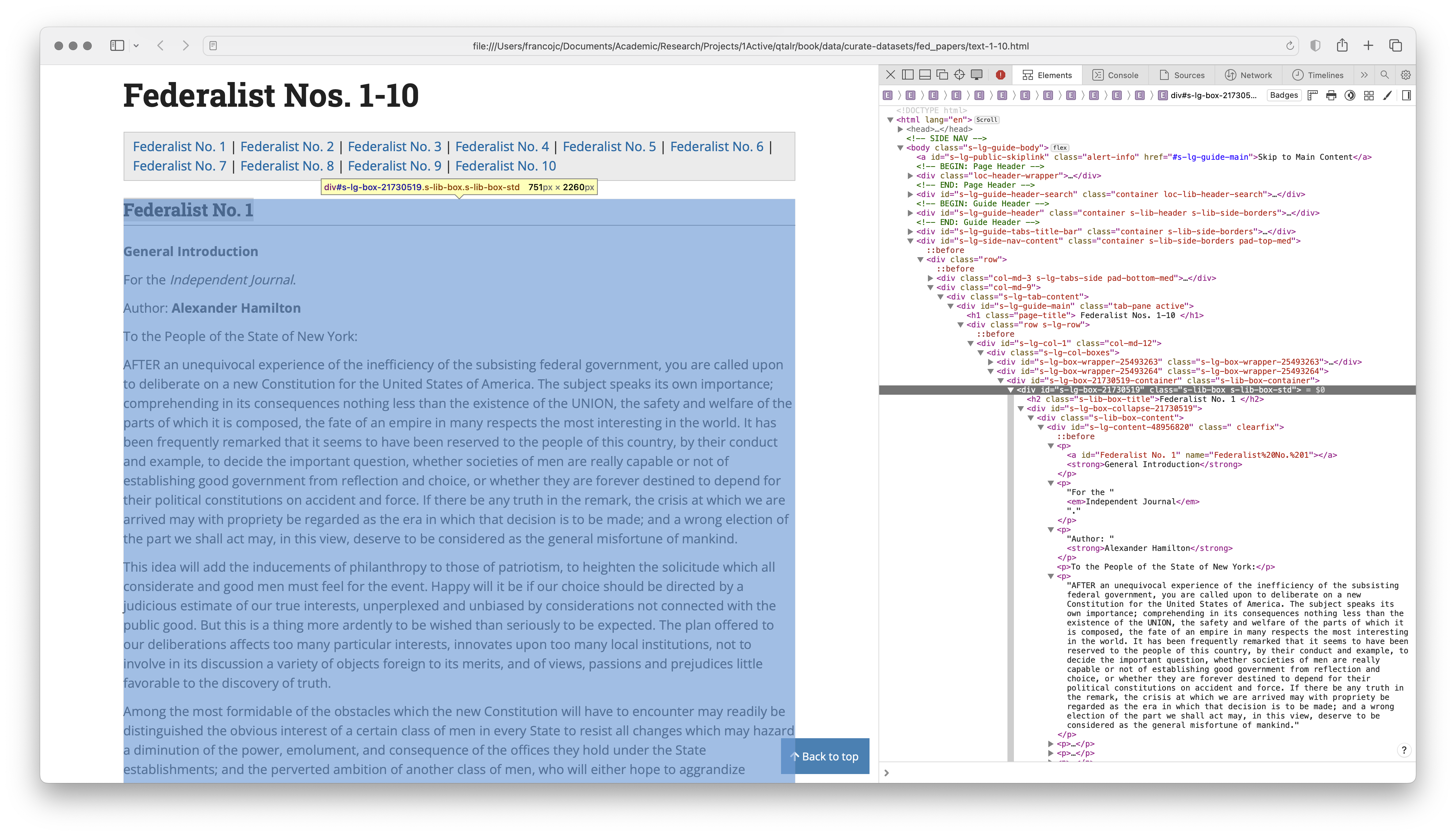
Figure 6: The HTML source code for the first paper in the text-1-10.html file.
The structure of the HTML files suggests that the desired content is within a div tag, which forms a kind of box around each paper. There are multiple div tags in the file, so we will need to find a way to identify the div tag that contains the desired content, and only this content. We can see that the div tag we want has two class attributes, s-lib-box s-lib-box-std. This div tag contains a h2 tag where the paper number appears. The first p tag contains the title of the paper. The second p tag contains the venue for the paper. The third p tag contains the author of the paper. The remaining p tags contain the text of the paper. A closer view of the div tag is shown in (fig-cd-federalist-html-inspect-2?).
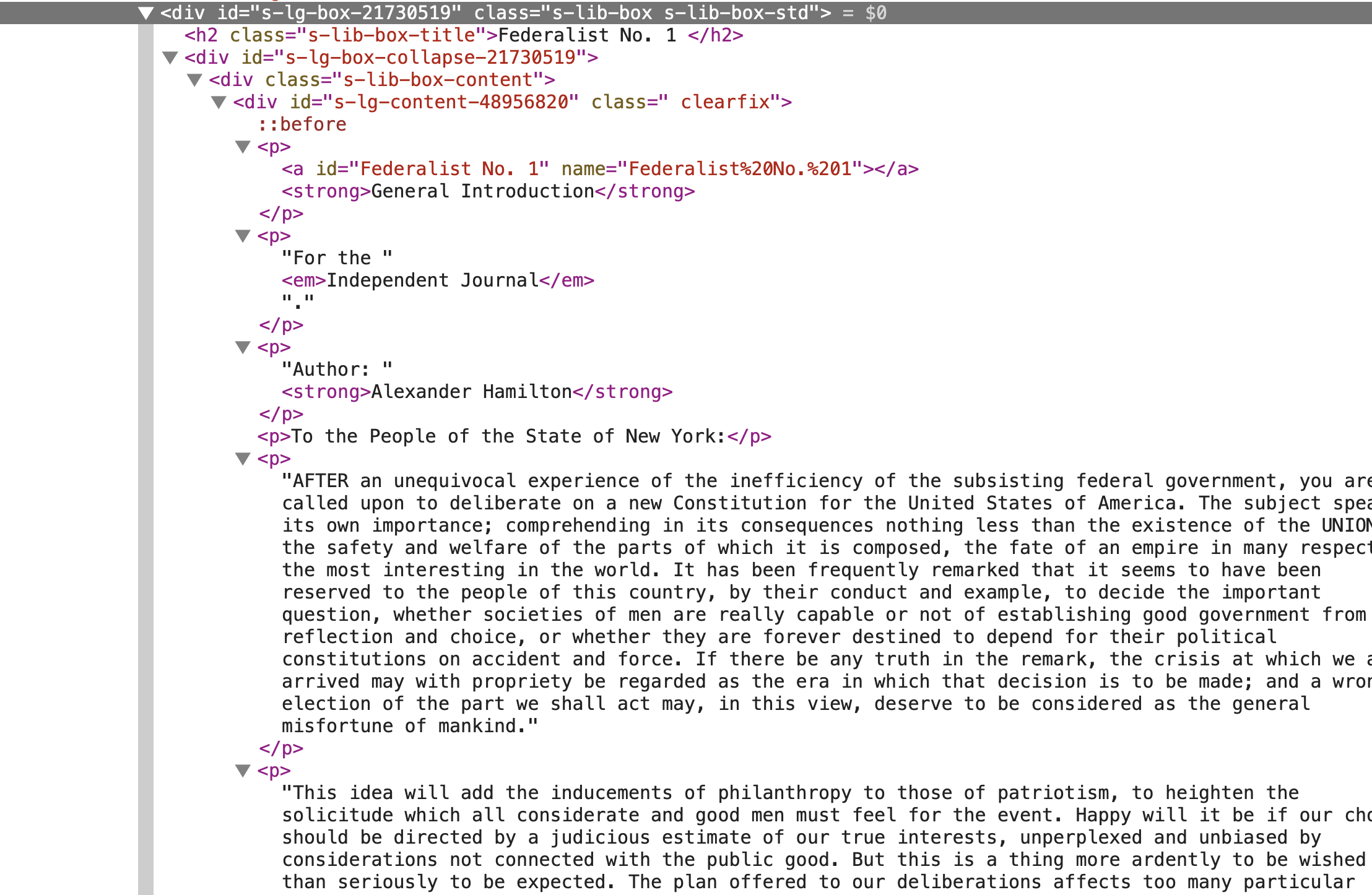
Figure 7: A closer view of the div tag containing the first paper in the text-1-10.html file.
Let's read in the text-1-10.html file and use it as a testing ground for extracting the relevant information. Load the rvest package and read in the file with read_html(), as in (exm-cd-federalist-html?).
## {html_document}
## <html lang="en">
## [1] <head>\n<meta http-equiv="X-UA-Compatible" content="IE=Edge">\n<meta http ...
## [2] <body class="s-lg-guide-body">\r\n<a id="s-lg-public-skiplink" class="ale ...Given what we discovered in the HTML inspection, let's extract the div tags with the s-lib-box s-lib-box-std class attributes. We can use the html_elements() function to extract the div tags and the append .s-lib-box.s-lib-box-std to the html_elements() function to specify the class attributes. (exm-cd-federalist-html-div?) shows the result assigned to an object called fed_divs.
## [1] "s-lib-box s-lib-box-std s-lib-floating-box"
## [2] "s-lib-box s-lib-box-std"
## [3] "s-lib-box s-lib-box-std"
## [4] "s-lib-box s-lib-box-std"
## [5] "s-lib-box s-lib-box-std"
## [6] "s-lib-box s-lib-box-std"
## [7] "s-lib-box s-lib-box-std"
## [8] "s-lib-box s-lib-box-std"
## [9] "s-lib-box s-lib-box-std"
## [10] "s-lib-box s-lib-box-std"
## [11] "s-lib-box s-lib-box-std"Using the html_attr("class") function we can see that the fed_divs object for this file contains 11 div tags, all the div tags we want, and one we don't which also includes the s-lib-floating-box class. We can exclude it by adding :not(.s-lib-floating-box) to the CSS selector. But it is worth checking out one or two other HTML files to see if this is a consistent pattern.
On inspection of other HTML files in our data, it turns out that only our first HTML file has the .s-lib-floating-box class. So a CSS solution might not be the way to go. An alternative, R-side solution is to use the div.s-lib-box, from above, and then subset the fed_divs vector to exclude the first element, which is where the extract div tag is located. (exm-cd-federalist-html-div-subset?) shows the result assigned to an object called fed_divs.
Assuming for the moment that the solution in (exm-cd-federalist-html-div-subset?) is the way to go, we can move forward to extract the paper number, title, author, and text from each div tag in fed_divs. We can use the html_elements() function to extract the h2 tag, which contains the paper number, and later work with the p tags, which contain the title, author, and text.
We've already isolated the relevant div tags, so using the fed_divs object we can now continue to use the html_elements() function to extract HTML elements within. The paper number is in a h2 tag, immediately after the div tag. We can use the html_element() function to extract a single h2 tag for each div in fed_divs, as in (exm-cd-federalist-html-h2?).
## {xml_nodeset (10)}
## [1] <h2 class="s-lib-box-title">Federalist No. 1\n ...
## [2] <h2 class="s-lib-box-title">Federalist No. 2\n ...
## [3] <h2 class="s-lib-box-title">Federalist No. 3\n ...
## [4] <h2 class="s-lib-box-title">Federalist No. 4\n ...
## [5] <h2 class="s-lib-box-title">Federalist No. 5\n ...
## [6] <h2 class="s-lib-box-title">Federalist No. 6\n ...
## [7] <h2 class="s-lib-box-title">Federalist No. 7\n ...
## [8] <h2 class="s-lib-box-title">Federalist No. 8\n ...
## [9] <h2 class="s-lib-box-title">Federalist No. 9\n ...
## [10] <h2 class="s-lib-box-title">Federalist No. 10\n ...The result is a vector which contains the h2 tag for each div tag in fed_divs, complete with all the HTML tags and attributes. We can use the html_text() function to extract the text from the h2 tag, as in (exm-cd-federalist-html-h2-text?).
## [1] "Federalist No. 1" "Federalist No. 2" "Federalist No. 3"
## [4] "Federalist No. 4" "Federalist No. 5" "Federalist No. 6"
## [7] "Federalist No. 7" "Federalist No. 8" "Federalist No. 9"
## [10] "Federalist No. 10"I included the str_trim() function from the stringr package to remove any potential whitespace from the text to the code in (exm-cd-federalist-html-h2-text?). The result is a vector of the paper numbers, which we can later leverage to create a new column in our dataset.
Next, we can extract the p tags from the fed_divs object. The p tags contain the title, author, and text. As noted above, the first p tag inside each div tag contains the paper title. Targeting this p tag requires the use of a CSS selector, :nth-child(). This CSS selector allows us to arbitrarily select the p tag we want in the order it appears. In this case, we want the first p tag, so we can use :nth-child(1). (exm-cd-federalist-html-p-title?) shows the result after extracting the text assigned to an object called titles.
## [1] "General Introduction"
## [2] "Concerning Dangers from Foreign Force and Influence"
## [3] "The Same Subject Continued: Concerning Dangers From Foreign Force and Influence"
## [4] "The Same Subject Continued: Concerning Dangers From Foreign Force and Influence"
## [5] "The Same Subject Continued: Concerning Dangers from Foreign Force and Influence"
## [6] "Concerning Dangers from Dissensions Between the States"
## [7] "The Same Subject Continued: Concerning Dangers from Dissensions Between the States"
## [8] "PUBLIUS."
## [9] "The Consequences of Hostilities Between the States"
## [10] "PUBLIUS."
## [11] "The Utility of the Union as a Safeguard Against Domestic Faction and Insurrection"
## [12] "PUBLIUS."
## [13] "The Same Subject Continued: The Union as a Safeguard Against Domestic Faction and Insurrection"{{< fa medal >}} Dive deeper
CSS selectors are a powerful tool for extracting data from HTML files. The :nth-child() selector is just one of many. For more information on CSS selectors, see the W3Schools CSS Selector Reference. The rvest package supports many, but not all CSS selectors. Consult the rvest::html_elements() documentation for more information.
We get a vector of length 13, not 10. Scanning the output we can see the most likely offender is the 'PUBLIUS.' text. We can exclude it by adding :not(:contains("PUBLIUS.")) to the CSS selector, as in (exm-cd-federalist-html-p-title-subset?).
## [1] "General Introduction"
## [2] "Concerning Dangers from Foreign Force and Influence"
## [3] "The Same Subject Continued: Concerning Dangers From Foreign Force and Influence"
## [4] "The Same Subject Continued: Concerning Dangers From Foreign Force and Influence"
## [5] "The Same Subject Continued: Concerning Dangers from Foreign Force and Influence"
## [6] "Concerning Dangers from Dissensions Between the States"
## [7] "The Same Subject Continued: Concerning Dangers from Dissensions Between the States"
## [8] "The Consequences of Hostilities Between the States"
## [9] "The Utility of the Union as a Safeguard Against Domestic Faction and Insurrection"
## [10] "The Same Subject Continued: The Union as a Safeguard Against Domestic Faction and Insurrection"That works, but this solution is 'brittle', meaning that it potentially overspecific and could easily break. For example, if the text of the title happens to include 'PUBLIUS.' it will be excluded. Furthermore, if the extra p tag contains some other text other than 'PUBLIUS.' it will be included.
We can make the solution more robust by looking for a more general solution. One possibility is to anchor the p tags to the div tag with the .clearfix class that appears directly above (>) the p tags we want, as in (exm-cd-federalist-html-p-title-subset-2?).
## [1] "General Introduction"
## [2] "Concerning Dangers from Foreign Force and Influence"
## [3] "The Same Subject Continued: Concerning Dangers From Foreign Force and Influence"
## [4] "The Same Subject Continued: Concerning Dangers From Foreign Force and Influence"
## [5] "The Same Subject Continued: Concerning Dangers from Foreign Force and Influence"
## [6] "Concerning Dangers from Dissensions Between the States"
## [7] "The Same Subject Continued: Concerning Dangers from Dissensions Between the States"
## [8] "The Consequences of Hostilities Between the States"
## [9] "The Utility of the Union as a Safeguard Against Domestic Faction and Insurrection"
## [10] "The Same Subject Continued: The Union as a Safeguard Against Domestic Faction and Insurrection"Now we have our 10 titles. Moving on to the author, we would assume could use the same approach as above changing the nth-child argument to 3. However, inspecting the HTML reveals that the author is not always the third p tag, sometimes it is the second. What is consistent, however, is that the author is always preceded by the text 'Author:'. We can use the :contains() CSS selector to select the p tag that contains the text 'Author:'.
With the result in (exm-cd-federalist-html-p-author?), we have now been able to extract the paper number, title and author. Our dataset is taking shape, as we can appreciate in (tbl-cd-federalist-html-dataset-preview?).
| number | title | author |
|---|---|---|
| Federalist No. 1 | General Introduction | Author: Alexander Hamilton |
| Federalist No. 2 | Concerning Dangers from Foreign Force and Influence | Author: John Jay |
| Federalist No. 3 | The Same Subject Continued: Concerning Dangers From Foreign Force and Influence | Author: John Jay |
| Federalist No. 4 | The Same Subject Continued: Concerning Dangers From Foreign Force and Influence | Author: John Jay |
| Federalist No. 5 | The Same Subject Continued: Concerning Dangers from Foreign Force and Influence | Author: John Jay |
| Federalist No. 6 | Concerning Dangers from Dissensions Between the States | Author: Alexander Hamilton |
| Federalist No. 7 | The Same Subject Continued: Concerning Dangers from Dissensions Between the States | Author: Alexander Hamilton |
| Federalist No. 8 | The Consequences of Hostilities Between the States | Author: Alexander Hamilton |
| Federalist No. 9 | The Utility of the Union as a Safeguard Against Domestic Faction and Insurrection | Author: Alexander Hamilton |
| Federalist No. 10 | The Same Subject Continued: The Union as a Safeguard Against Domestic Faction and Insurrection | Author: James Madison |
The last step is to extract the text of the paper. The contents of the papers are contained in the p tags that follow the p tag with the author. It would be nice to be able to target the p tags that follow the author p tag. However, there is no CSS selector that allows us to do this. An alternative is to read all the p tags in each div.clearfix tag and then select the p tags that follow the author p tag.
This approach requires an additional step. We need to conduct this process for each paper in the HTML file separate
the str_which() function to identify the index of the p tag that contains the author. We can then use the str_subset() function to select all the p tags that follow the author p tag.
## [1] "To the People of the State of New York:"
## [2] "AFTER an unequivocal experience of the inefficiency of the subsisting federal government, you are called upon to deliberate on a new Constitution for the United States of America. The subject speaks its own importance; comprehending in its consequences nothing less than the existence of the UNION, the safety and welfare of the parts of which it is composed, the fate of an empire in many respects the most interesting in the world. It has been frequently remarked that it seems to have been reserved to the people of this country, by their conduct and example, to decide the important question, whether societies of men are really capable or not of establishing good government from reflection and choice, or whether they are forever destined to depend for their political constitutions on accident and force. If there be any truth in the remark, the crisis at which we are arrived may with propriety be regarded as the era in which that decision is to be made; and a wrong election of the part we shall act may, in this view, deserve to be considered as the general misfortune of mankind."This gets the text for a single paper within a single div tag. We can wrap this in a function and apply it to each div tag.
Now we can see what the text looks like for the first paper.
## # A tibble: 163 × 4
## number title author text
## <chr> <chr> <chr> <chr>
## 1 Federalist No. 1 General Introduction Author: Alexander Hamilton To the Peop…
## 2 Federalist No. 1 General Introduction Author: Alexander Hamilton AFTER an un…
## 3 Federalist No. 1 General Introduction Author: Alexander Hamilton This idea w…
## 4 Federalist No. 1 General Introduction Author: Alexander Hamilton Among the m…
## 5 Federalist No. 1 General Introduction Author: Alexander Hamilton It is not, …
## 6 Federalist No. 1 General Introduction Author: Alexander Hamilton And yet, ho…
## 7 Federalist No. 1 General Introduction Author: Alexander Hamilton In the cour…
## 8 Federalist No. 1 General Introduction Author: Alexander Hamilton I propose, …
## 9 Federalist No. 1 General Introduction Author: Alexander Hamilton THE UTILITY…
## 10 Federalist No. 1 General Introduction Author: Alexander Hamilton In the prog…
## # ℹ 153 more rowsPutting these together for the first HTML file we get the following.
We can test this on the first HTML file.
## Rows: 163
## Columns: 4
## $ number <chr> "Federalist No. 1", "Federalist No. 1", "Federalist No. 1", "Fe…
## $ title <chr> "General Introduction", "General Introduction", "General Introd…
## $ author <chr> "Author: Alexander Hamilton", "Author: Alexander Hamilton", "Au…
## $ text <chr> "To the People of the State of New York:", "AFTER an unequivoca…Let's try the fifth HTML file, just to make sure.
## Rows: 56
## Columns: 4
## $ number <chr> "Federalist No. 51", "Federalist No. 51", "Federalist No. 52", …
## $ title <chr> "The Structure of the Government Must Furnish the Proper Checks…
## $ author <chr> "Author: Alexander Hamilton or James Madison", "Author: Alexand…
## $ text <chr> "To the People of the State of New York:", "TO WHAT expedient, …Now we can apply this function to all the HTML files.
## Rows: 1,073
## Columns: 4
## $ number <chr> "Federalist No. 1", "Federalist No. 1", "Federalist No. 1", "Fe…
## $ title <chr> "General Introduction", "General Introduction", "General Introd…
## $ author <chr> "Author: Alexander Hamilton", "Author: Alexander Hamilton", "Au…
## $ text <chr> "To the People of the State of New York:", "AFTER an unequivoca…We can do some data checks to make sure we have the right number of rows and columns.
## # A tibble: 7 × 2
## author author_count
## <chr> <int>
## 1 Author: Alexander Hamilton 659
## 2 Author: Alexander Hamilton and James Madison 25
## 3 Author: Alexander Hamilton or James Madison 93
## 4 Author: James Madison 147
## 5 Author: John Jay 81
## 6 Author: Alexander Hamilton 27
## 7 Author: Alexander Hamilton and James Madison 41## # A tibble: 85 × 2
## number number_count
## <chr> <int>
## 1 Federalist No. 1 11
## 2 Federalist No. 10 24
## 3 Federalist No. 11 15
## 4 Federalist No. 12 13
## 5 Federalist No. 13 5
## 6 Federalist No. 14 13
## 7 Federalist No. 15 16
## 8 Federalist No. 16 12
## 9 Federalist No. 17 15
## 10 Federalist No. 18 21
## 11 Federalist No. 19 20
## 12 Federalist No. 2 15
## 13 Federalist No. 20 25
## 14 Federalist No. 21 14
## 15 Federalist No. 22 19
## 16 Federalist No. 23 13
## 17 Federalist No. 24 14
## 18 Federalist No. 25 11
## 19 Federalist No. 26 15
## 20 Federalist No. 27 7
## 21 Federalist No. 28 11
## 22 Federalist No. 29 14
## 23 Federalist No. 3 19
## 24 Federalist No. 30 12
## 25 Federalist No. 31 13
## 26 Federalist No. 32 6
## 27 Federalist No. 33 9
## 28 Federalist No. 34 12
## 29 Federalist No. 35 12
## 30 Federalist No. 36 18
## 31 Federalist No. 37 17
## 32 Federalist No. 38 12
## 33 Federalist No. 39 17
## 34 Federalist No. 4 18
## 35 Federalist No. 40 3
## 36 Federalist No. 41 6
## 37 Federalist No. 42 7
## 38 Federalist No. 43 7
## 39 Federalist No. 44 7
## 40 Federalist No. 45 8
## 41 Federalist No. 46 9
## 42 Federalist No. 47 8
## 43 Federalist No. 48 7
## 44 Federalist No. 49 5
## 45 Federalist No. 5 13
## 46 Federalist No. 50 7
## 47 Federalist No. 51 2
## 48 Federalist No. 52 6
## 49 Federalist No. 53 4
## 50 Federalist No. 54 5
## 51 Federalist No. 55 9
## 52 Federalist No. 56 4
## 53 Federalist No. 57 9
## 54 Federalist No. 58 2
## 55 Federalist No. 59 2
## 56 Federalist No. 6 20
## 57 Federalist No. 60 13
## 58 Federalist No. 61 7
## 59 Federalist No. 62 20
## 60 Federalist No. 63 22
## 61 Federalist No. 64 16
## 62 Federalist No. 65 12
## 63 Federalist No. 66 15
## 64 Federalist No. 67 12
## 65 Federalist No. 68 11
## 66 Federalist No. 69 12
## 67 Federalist No. 7 11
## 68 Federalist No. 70 25
## 69 Federalist No. 71 8
## 70 Federalist No. 72 15
## 71 Federalist No. 73 16
## 72 Federalist No. 74 5
## 73 Federalist No. 75 9
## 74 Federalist No. 76 11
## 75 Federalist No. 77 11
## 76 Federalist No. 78 22
## 77 Federalist No. 79 6
## 78 Federalist No. 8 14
## 79 Federalist No. 80 22
## 80 Federalist No. 81 20
## 81 Federalist No. 82 7
## 82 Federalist No. 83 38
## 83 Federalist No. 84 22
## 84 Federalist No. 85 15
## 85 Federalist No. 9 18Write the data
...