library(dplyr) # for data manipulation
library(stringr) # for string manipulation
library(tidyr) # for data tidying
library(tidytext) # for text analysis
library(ggplot2) # for data visualization08. Employing exploratory methods
Descriptive analysis and unsupervised machine learning
analysis
Exploratory analysis is a wide-ranging term that encompasses many different methods. In this recipe, we will focus on the methods that are most commonly used in the analysis of textual data. These include frequency and distributional analysis, clustering, and word embedding models.
The approach to exploratory analysis is rarely linear, but rather an interative cycle of the steps in Table 1. This cycle is repeated until the research question(s) have been addressed.
| Step | Name | Description |
|---|---|---|
| 1 | Identify | Consider the research question and identify variables of potential interest to provide insight into our question. |
| 2 | Inspect | Check for missing data, outliers, etc. and check data distributions and transform if necessary. |
| 3 | Interrogate | Submit the selected variables to descriptive or unsupervised learning methods to provide quantitative measures to evaluate. |
| 4 | Interpret | Evaluate the results and determine if they are valid and meaningful to respond to the research question. |
We will model how to explore iteratively using the output of one method to inform the next and ultimately to address the research question. For this reason, the subsequent sections of this recipe are grouped by research question rather than by approach step or method.
Let’s get started by loading some of the packages we will likely use.
Concepts and strategies
Orientation
We will use the SOTU corpus to demonstrate the different methods. We will select a subset of the corpus (post-1945) and explore the question:
- How has the language of the SOTU changed over time?
This will include methods such as frequency and distributional analysis, dimensionality reduction, and word embedding models.
Let’s look at the first few rows of the data to get a sense of what we have.
sotu_df# # A tibble: 73 × 4
# president year party address
# <chr> <dbl> <chr> <chr>
# 1 Truman 1947 Democratic "Mr. President, Mr. Speaker, Members of the Cong…
# 2 Truman 1948 Democratic "Mr. President, Mr. Speaker, and Members of the …
# 3 Truman 1949 Democratic "Mr. President, Mr. Speaker, Members of the Cong…
# 4 Truman 1950 Democratic "Mr. President, Mr. Speaker, Members of the Cong…
# 5 Truman 1951 Democratic "Mr. President, Mr. Speaker, Members of the Cong…
# 6 Truman 1952 Democratic "Mr. President, Mr. Speaker, Members of the Cong…
# 7 Eisenhower 1953 Republican "Mr. President, Mr. Speaker, Members of the Eigh…
# 8 Eisenhower 1954 Republican "Mr. President, Mr. Speaker, Members of the Eigh…
# 9 Eisenhower 1955 Republican "Mr. President, Mr. Speaker, Members of the Cong…
# 10 Eisenhower 1956 Republican "My Fellow Citizens: This morning I sent to the …
# # ℹ 63 more rowsWe can see that the dataset contains the president, year, party, and address for each SOTU address.
Now let’s view a statistical overview summary of the data by using the skim() function.
skimr::skim(sotu_df)# ── Data Summary ────────────────────────
# Values
# Name sotu_df
# Number of rows 73
# Number of columns 4
# _______________________
# Column type frequency:
# character 3
# numeric 1
# ________________________
# Group variables None
#
# ── Variable type: character ────────────────────────────────────────────────────
# skim_variable n_missing complete_rate min max empty n_unique whitespace
# 1 president 0 1 4 10 0 12 0
# 2 party 0 1 10 10 0 2 0
# 3 address 0 1 6160 51947 0 73 0
#
# ── Variable type: numeric ──────────────────────────────────────────────────────
# skim_variable n_missing complete_rate mean sd p0 p25 p50 p75 p100
# 1 year 0 1 1984. 21.6 1947 1965 1984 2002 2020
# hist
# 1 ▇▇▇▇▇We can see that the dataset contains 73 rows –corresponding to the number of SOTU addresses. Looking at missing values, we can see that there are no missing values for any of the variables. Taking a closer look at each variable, the president variable is a character vector with 12 unique presidents. There are two unique parties and 73 unique addresses. The year variable is numeric with a minimum value of 1947 and a maximum value of 2020, therefore the addresses include 73 years.
Identify
With a general sense of the data, we can now move on to the first step in the exploratory analysis workflow: identifying variables of interest.
- What linguistic variables might be of interest to address this question?
Words might be the most obvious variable, but we might also be interested in other linguistic variables such as parts of speech, syntactic structures, or some combination of these.
Let’s start with words. If we look at words, we might be interested in the frequency of words, the distribution of words, or the meaning of words. We might also be interested in the relationship between words. For example, we might be interested in the co-occurrence of words or the similarity of words. These, and more, are all possible approaches that we might consider.
Another consideration is if we want to do comparisons across time, across presidents, across parties, etc.. In our research question, we have already identified that we want to compare across time so that will be our focus. However, what we mean by “time” is not clear. Do we mean across years, across decades, across presidencies, etc.? We will need to make a decision about how we want to define time, but we can fold this into our exploratory analysis, as we will see below.
Let’s posit the following sub-questions:
- What are the most frequent words across time periods?
- How does the distribution of words change across time periods?
- How does the meaning of words change across time periods?
We will use these sub-questions to guide our exploratory analysis.
Inspect
The next step is to inspect the data. We will transform the data as necessary to prepare it for analysis and then do some diagnostic checks to make sure that the data is ready for analysis.
Since we will be working with words, let’s tokenize the addresses variable to extract the words and maintain a tidy dataset. We will use the unnest_tokens() function from {tidytext} to do this. Let’s apply the function and assign the result to a new variable called sotu_words_df.
# Tokenize the words by year (with numbers removed)
sotu_words_df <-
sotu_df |>
unnest_tokens(word, address, strip_numeric = TRUE)Let’s continue by looking at whether there is a relationship between the number of words and years. We can do this by using the count() function on the year variable. This will group and count the number of observations (words) per year as n.
We can then visualize this with a line plot where the x-axis is the year and the y-axis is the number of words n. I’ll add the plot to a variable called p so that we can add layers to it.
# Get the number of words per year --------------------------------
p <-
sotu_words_df |>
count(year) |>
ggplot(aes(x = year, y = n)) +
geom_line()
# View
p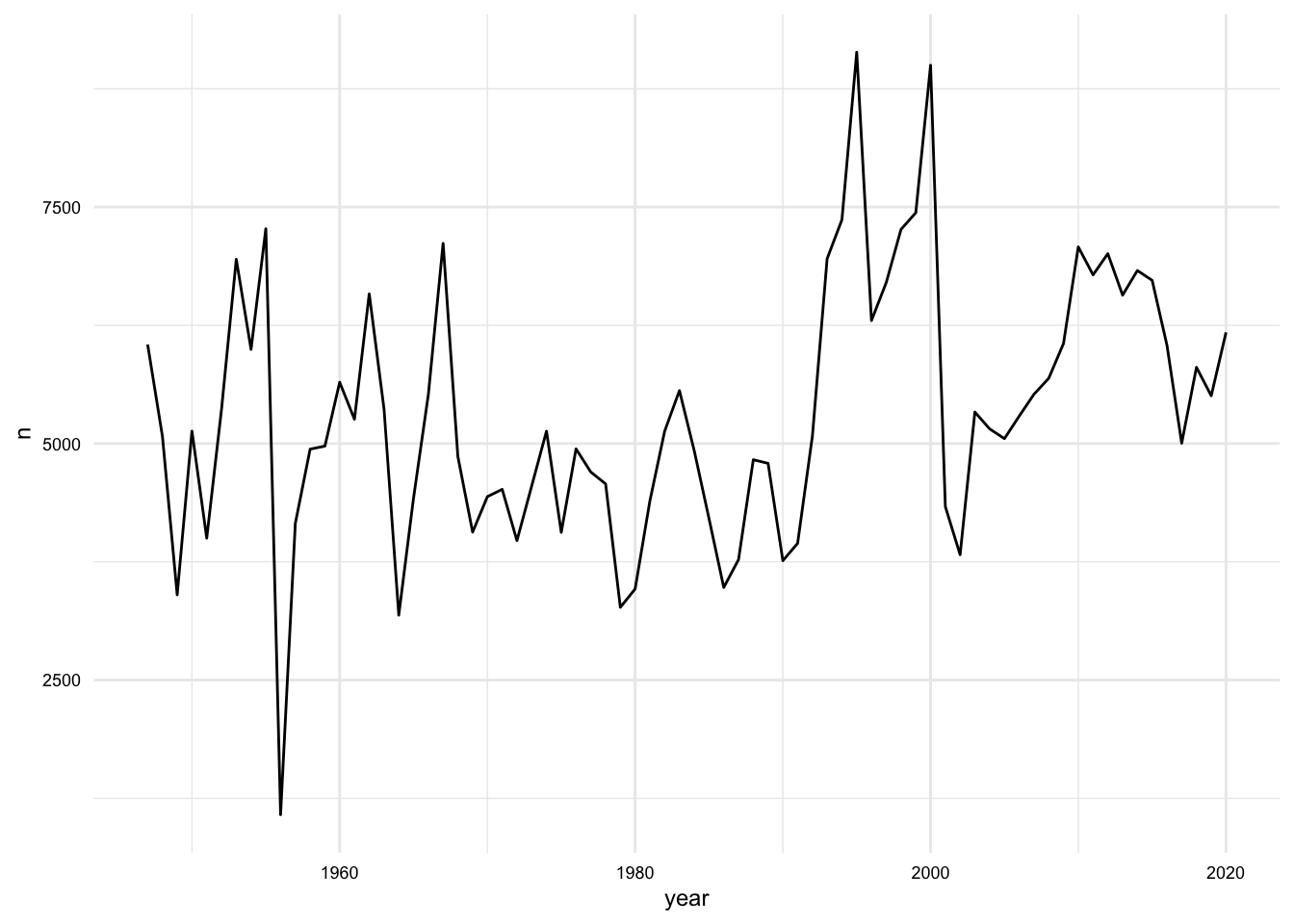
We can see from Figure 2 that the number of words per year varies, sometimes quite a bit. To get a sense of the relationship between the number of words and the year, we can add a linear trend line to the plot. We can do this by adding the geom_smooth() function to the plot. We will set the method argument to "lm" to use a linear model.
p + geom_smooth(method = "lm")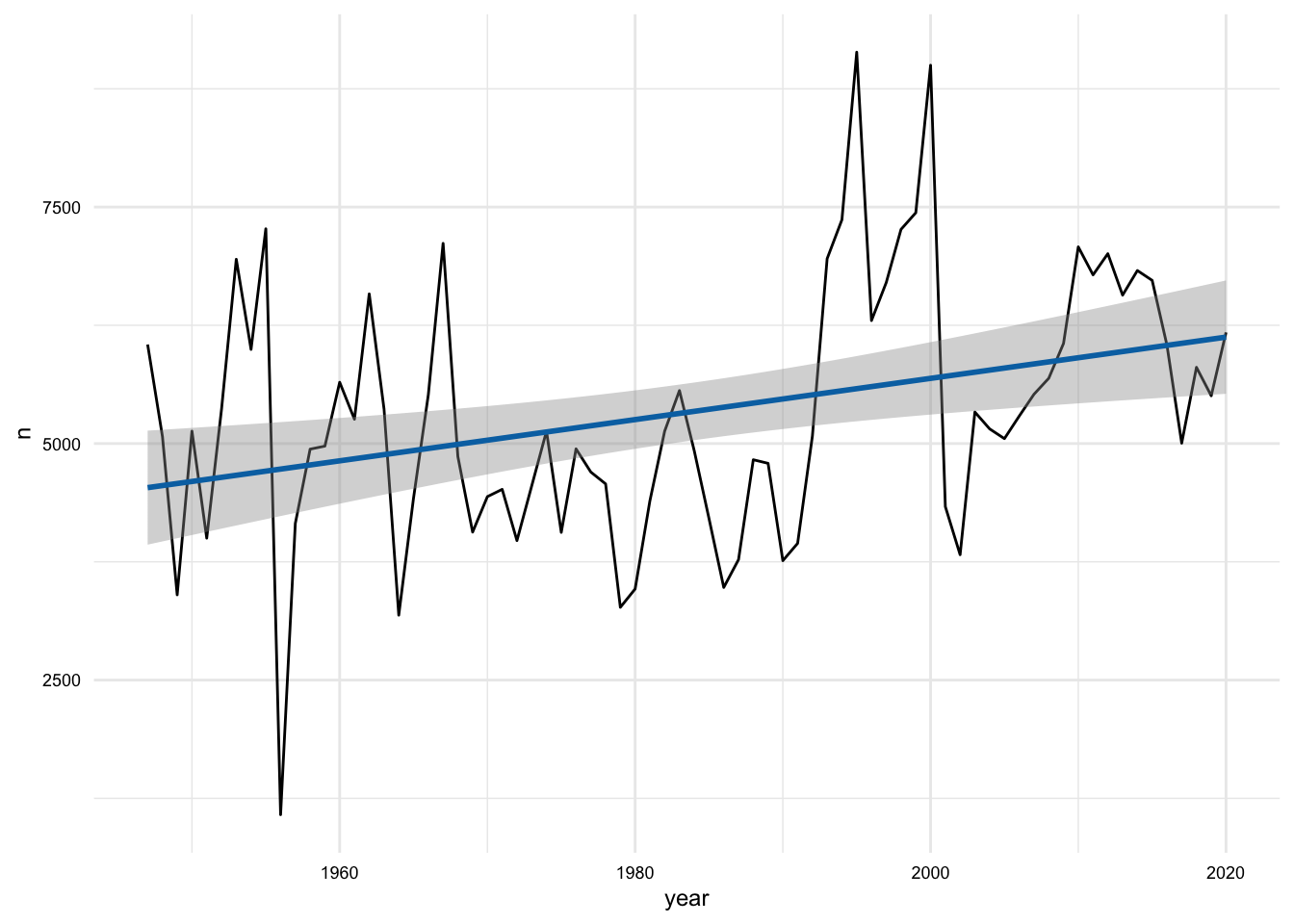
This plot shows that there is a positive relationship between the number of words and the year –that is the number of words increases over time. But the line is not a great fit and furthermore the angle of the line is more horizontal than vertical. This suggests that the relationship is not a strong one. We can confirm this by calculating the correlation between the number of words and the year. We can do this by using the cor.test() function on the year and n variables inside a summarize() function.
# Get the correlation between the number of words and the year ----
sotu_words_df |>
count(year) |>
summarize(cor = cor.test(year, n)$estimate)# A tibble: 1 × 1
cor
<dbl>
1 0.342So, even though we are working to inspect our data, we already have a finding. The number of words increases over time, despite the fact that the relationship is not a strong one.
Now, let’s turn our attention to the frequency of individual words. Let’s start by looking at the most frequent words for the entire corpus. We can do this by grouping by the word variable and then summarizing the number of times each word occurs. We will then arrange the data in descending order by the number of times each word occurs.
# Get the most frequent words ------------------------------------
sotu_words_df |>
count(word, sort = TRUE) |>
slice_head(n = 10)# A tibble: 10 × 2
word n
<chr> <int>
1 the 21565
2 and 14433
3 to 13679
4 of 13087
5 in 8116
6 we 7327
7 a 7137
8 our 6822
9 that 5391
10 for 4513The usual suspects are at the top of the list. This is not surprising, and will likely be the case for most corpora, and sizeable subcorpora –in our case the time periods. Let’s address this.
We could use a stopwords list to just eliminate many of these common words, but that might be a bit too agressive and we will likely lose some words that we want to keep. Considering a more nuanced approach, we will use the \(tf\)-\(idf\) transformation to attenuate the effect of words that are common across all time periods, and on the flip side, to promote the effect of words that are more distinctive to each time period.
In order to do this, we will need to calculate the \(tf\)-\(idf\) for each word in each time period. To keep things simple, we will calculate the \(tf\)-\(idf\) for each word in each decade. We will do this by creating a new variable called decade that is the year rounded down to the nearest decade. Then we can group by this decade variable and then count the number of times each word occurs. We will then calculate the \(tf\)-\(idf\) for each word in each decade using the bind_tf_idf() function from {tidytext}. We will then arrange the data in descending order by the \(tf\)-\(idf\) value.
# Get the tf-idf of words by decade ------------------------------
sotu_words_tfidf_df <-
sotu_words_df |>
mutate(decade = floor(year / 10) * 10) |>
count(decade, word) |>
bind_tf_idf(word, decade, n) |>
arrange(decade, desc(tf_idf))
# Preview
sotu_words_tfidf_df# A tibble: 40,073 × 6
decade word n tf idf tf_idf
<dbl> <chr> <int> <dbl> <dbl> <dbl>
1 1940 boycotts 5 0.000344 2.20 0.000756
2 1940 jurisdictional 7 0.000482 1.50 0.000725
3 1940 interpretation 4 0.000275 2.20 0.000605
4 1940 unjustified 4 0.000275 2.20 0.000605
5 1940 insecurity 5 0.000344 1.50 0.000518
6 1940 arbitration 3 0.000207 2.20 0.000454
7 1940 output 6 0.000413 1.10 0.000454
8 1940 unjustifiable 3 0.000207 2.20 0.000454
9 1940 management 25 0.00172 0.251 0.000433
10 1940 rental 4 0.000275 1.50 0.000414
# ℹ 40,063 more rowsOK. Even the preview shows that we are getting a more interesting list of words.
Let’s look at the top 10 words for each decade. We group by decade and then slice the top 10 words by \(tf\)-\(idf\) value with slice_max(). Then we will use the reorder_within() function from {tidytext} to reorder the words within each facet by the \(tf\)-\(idf\) value.
We will visualize this with a bar chart where word is on the x-axis and the height of the bar is the \(tf\)-\(idf\) value. We will also facet the plot by decade. I’ve flipped the coordinates so that the words are on the y-axis and the bars are horizontal. This is a personal preference, but I find it easier to read the words this way.
sotu_words_tfidf_df |>
group_by(decade) |>
slice_max(n = 10, tf_idf) |>
ungroup() |>
mutate(decade = as.character(decade)) |>
mutate(word = reorder_within(word, desc(tf_idf), decade)) |>
ggplot(aes(word, tf_idf, fill = decade)) +
geom_col() +
scale_x_reordered() +
facet_wrap(~decade, scales = "free") +
theme(legend.position = "none") +
coord_flip()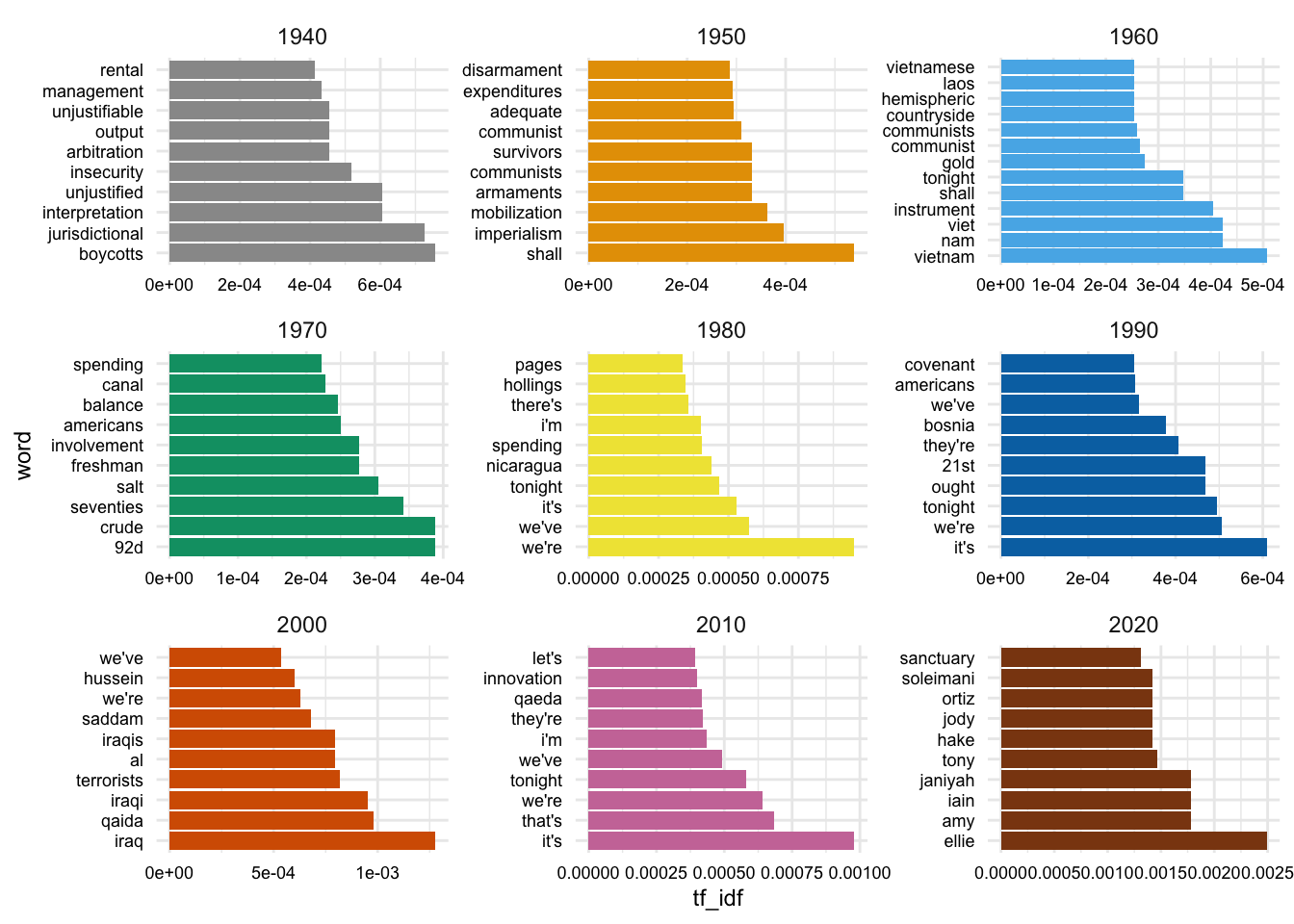
Scanning the top words for the decades we can see some words that signal contemporary issues. This is a hint that we are picking up on some of the changes in the language of the SOTU over time.
To my eye, however, the 1940s and the 2020s don’t seem to jump out at me in the same way. Let’s take a closer look at the 1940s and the 2020s in our original dataset.
sotu_df |>
filter(year < 1950 | year >= 2020)# A tibble: 4 × 4
president year party address
<chr> <dbl> <chr> <chr>
1 Truman 1947 Democratic "Mr. President, Mr. Speaker, Members of the Congre…
2 Truman 1948 Democratic "Mr. President, Mr. Speaker, and Members of the 80…
3 Truman 1949 Democratic "Mr. President, Mr. Speaker, Members of the Congre…
4 Trump 2020 Republican "Madam Speaker, Mr. Vice President, Members of Con…Well, that explains it. There are only 3 addresses in the 1940s and 1 address in the 2020s. This is not enough data to get a good sense of the language of the SOTU for these decades. Let’s remove these decades from our original dataset as not being representative of the language of the SOTU.
Another consideration that catches my eye in looking at the top words by decade is that our words like “communist” and “communists” are being counted separately. That is fine, but what if we want to count these as the same word? We can do this by lemmatizing the words –that is reducing the words to their root form. We can do this using the lemmatize_words() function from {textstem}.
So consider this example:
# Lemmatize the words --------------------------------------------
words_chr <- c("freedom", "free", "frees", "freeing", "freed")
textstem::lemmatize_words(words_chr)[1] "freedom" "free" "free" "free" "free" With these considerations in mind, let’s update our sotu_df dataset to remove the 1940s and 2020s, tokenize and lemmatize the words, and add a decade variable.
# Update the dataset ----------------------------------------------
sotu_terms_df <-
sotu_df |>
filter(year >= 1950 & year < 2020) |> # Remove the 1940s and 2020s
unnest_tokens(word, address, strip_numeric = TRUE) |> # Tokenize the words
mutate(lemma = textstem::lemmatize_words(word)) |> # Lemmatize the words
mutate(decade = floor(year / 10) * 10) |> # Add a decade variable
select(president, decade, year, party, word, lemma) #
# Preview
sotu_terms_df# A tibble: 368,586 × 6
president decade year party word lemma
<chr> <dbl> <dbl> <chr> <chr> <chr>
1 Truman 1950 1950 Democratic mr mr
2 Truman 1950 1950 Democratic president president
3 Truman 1950 1950 Democratic mr mr
4 Truman 1950 1950 Democratic speaker speaker
5 Truman 1950 1950 Democratic members member
6 Truman 1950 1950 Democratic of of
7 Truman 1950 1950 Democratic the the
8 Truman 1950 1950 Democratic congress congress
9 Truman 1950 1950 Democratic a a
10 Truman 1950 1950 Democratic year year
# ℹ 368,576 more rowsThis inspection process could go on for a while. We could continue to inspect the data and make changes to the dataset but it is often the case that in the process of analysis we will often run into issues that require us to go back and make changes to the dataset. So we will move on to the next step in the exploratory analysis workflow.
Interrogate
Now that we have our data in a tidy format, we can move on to the next step in the exploratory analysis workflow: interrogating the data. We will submit the selected variables to descriptive or unsupervised learning methods to provide quantitative measures to evaluate.
Frequency
- What are the most frequent words across time periods?
We have already made some progress on this question in the inspection phase, but now we can do it again with the updated dataset.
# Get the most frequent lemmas by decade --------------------------
sotu_lemmas_tfidf_df <-
sotu_terms_df |>
count(decade, lemma) |> # Count the lemmas by decade
bind_tf_idf(lemma, decade, n) |> # Calculate the tf-idf
arrange(decade, desc(tf_idf))
# Preview
sotu_lemmas_tfidf_df# A tibble: 26,435 × 6
decade lemma n tf idf tf_idf
<dbl> <chr> <int> <dbl> <dbl> <dbl>
1 1950 armament 16 0.000321 1.95 0.000625
2 1950 imperialism 9 0.000181 1.95 0.000351
3 1950 shall 107 0.00215 0.154 0.000331
4 1950 disarmament 13 0.000261 1.25 0.000327
5 1950 mineral 8 0.000160 1.95 0.000312
6 1950 mobilization 12 0.000241 1.25 0.000302
7 1950 survivor 12 0.000241 1.25 0.000302
8 1950 expenditure 42 0.000842 0.336 0.000283
9 1950 adequate 25 0.000501 0.560 0.000281
10 1950 constantly 11 0.000221 1.25 0.000276
# ℹ 26,425 more rowsNow we can visualize the top 10 lemmas for each decade, as we did above, but for the lemmas instead of the words and for seven full decades.
sotu_lemmas_tfidf_df |>
group_by(decade) |>
slice_max(n = 10, tf_idf) |>
ungroup() |>
mutate(decade = as.character(decade)) |>
mutate(lemma = reorder_within(lemma, desc(tf_idf), decade)) |>
ggplot(aes(lemma, tf_idf, fill = decade)) +
geom_col() +
scale_x_reordered() +
facet_wrap(~decade, scales = "free") +
theme(legend.position = "none") +
coord_flip()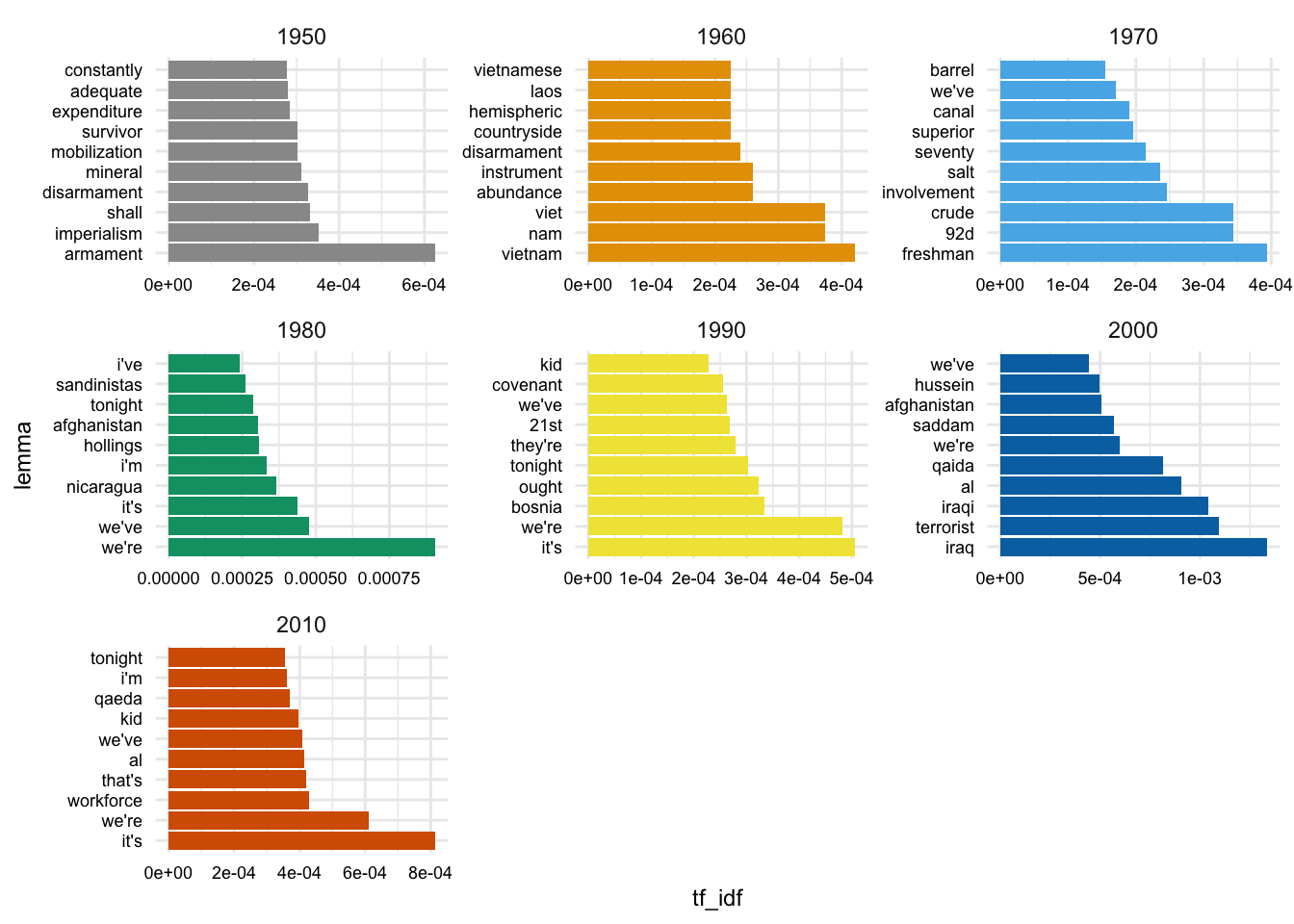
Distribution
- How does the distribution of words change across time periods?
OK. Now let’s focus on word frequency distributions over time. We will return to the sotu_terms_df.
sotu_terms_df# A tibble: 368,586 × 6
president decade year party word lemma
<chr> <dbl> <dbl> <chr> <chr> <chr>
1 Truman 1950 1950 Democratic mr mr
2 Truman 1950 1950 Democratic president president
3 Truman 1950 1950 Democratic mr mr
4 Truman 1950 1950 Democratic speaker speaker
5 Truman 1950 1950 Democratic members member
6 Truman 1950 1950 Democratic of of
7 Truman 1950 1950 Democratic the the
8 Truman 1950 1950 Democratic congress congress
9 Truman 1950 1950 Democratic a a
10 Truman 1950 1950 Democratic year year
# ℹ 368,576 more rowsWe want to get a sense of how the word distributions change over time. We need to calculate the frequency of words for each year, first off. So we need to go back to the sotu_terms_df dataset and group by year and word and then count the number of times each word occurs.
Since we will lose the lemma variable in this process, we will add it back after the \(tf\)-\(idf\) transformation by using the mutate() function and the textstem::lemmatize_words() function.
sotu_terms_tfidf_df <-
sotu_terms_df |>
count(year, word) |> # Count the words by year
bind_tf_idf(word, year, n) |> # Calculate the tf-idf
mutate(lemma = textstem::lemmatize_words(word)) |> # Lemmatize the words
arrange(year, desc(tf_idf))
# Preview
sotu_terms_tfidf_df# A tibble: 97,213 × 7
year word n tf idf tf_idf lemma
<dbl> <chr> <int> <dbl> <dbl> <dbl> <chr>
1 1950 enjoyment 3 0.000585 3.54 0.00207 enjoyment
2 1950 rent 3 0.000585 2.85 0.00167 rend
3 1950 widespread 3 0.000585 2.85 0.00167 widespread
4 1950 underdeveloped 2 0.000390 4.23 0.00165 underdeveloped
5 1950 ideals 7 0.00136 1.14 0.00156 ideal
6 1950 transmit 3 0.000585 2.62 0.00153 transmit
7 1950 peoples 8 0.00156 0.976 0.00152 people
8 1950 democratic 12 0.00234 0.623 0.00146 democratic
9 1950 expenditures 7 0.00136 1.06 0.00144 expenditure
10 1950 businessmen 3 0.000585 2.44 0.00143 businessman
# ℹ 97,203 more rowsWith this format, we can visualize the distinctiveness of words over time. All we need to do is to filter the data to the lemmas we are interested first.
Let’s just start with some random poltical-oriented words.
plot_terms <- c("crime", "law", "free", "terror", "family", "government")
sotu_terms_tfidf_df |>
filter(lemma %in% plot_terms) |>
ggplot(aes(year, tf_idf)) +
geom_smooth(se = FALSE, span = 0.25) +
facet_wrap(~lemma, scales = "free_y")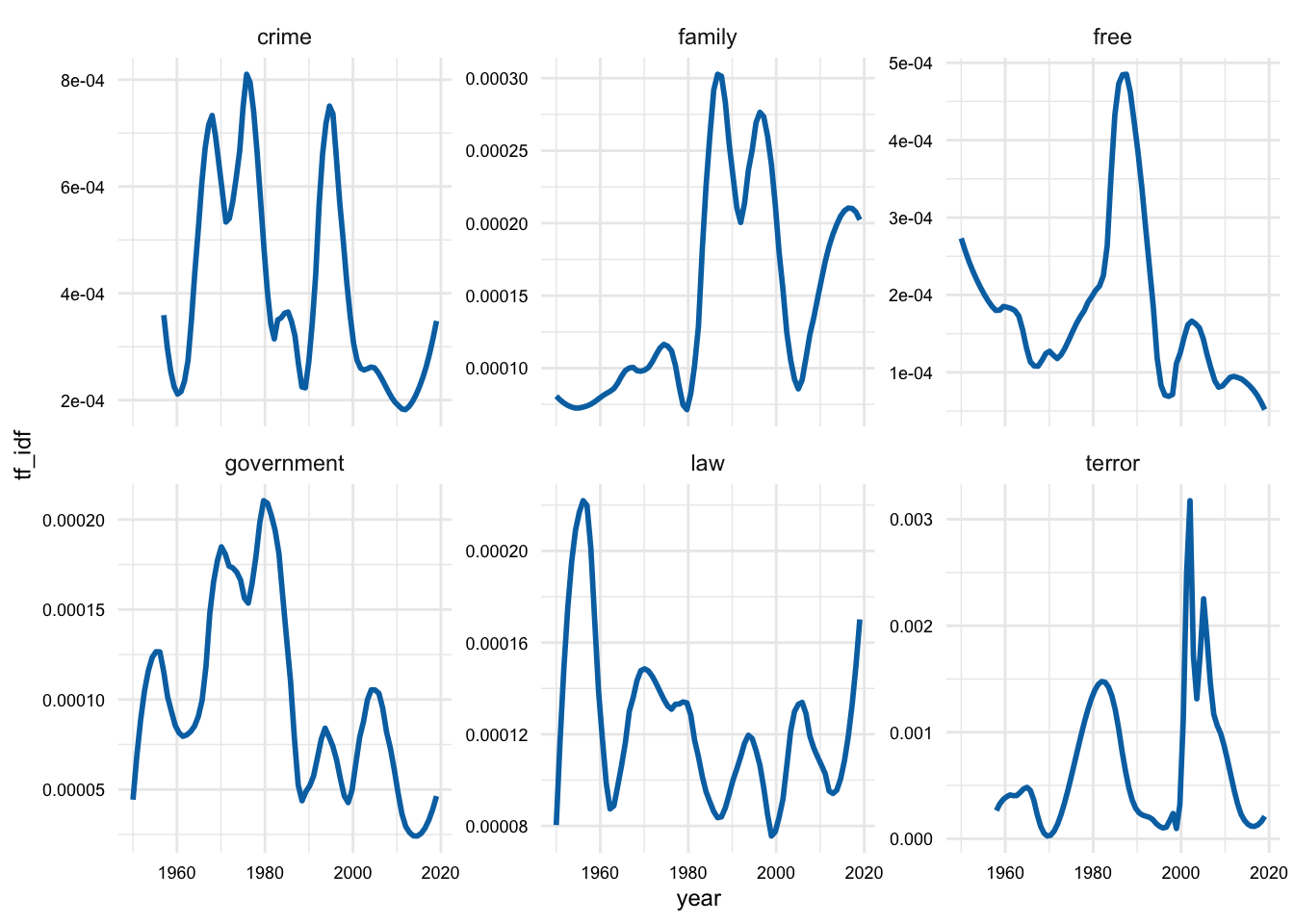
We can see in Figure 5 that the distinctiveness of these lemmas varies over time. Now, in this plot I’ve used a small span value for the geom_smooth() function to get a sense of the more fine-grained changes over time. However, this is may be too fine-grained. We can adjust this by increasing the span value. Let’s try a span value of 0.5.
sotu_terms_tfidf_df |>
filter(lemma %in% plot_terms) |>
ggplot(aes(year, tf_idf)) +
geom_smooth(se = FALSE, span = 0.5) +
facet_wrap(~lemma, scales = "free_y")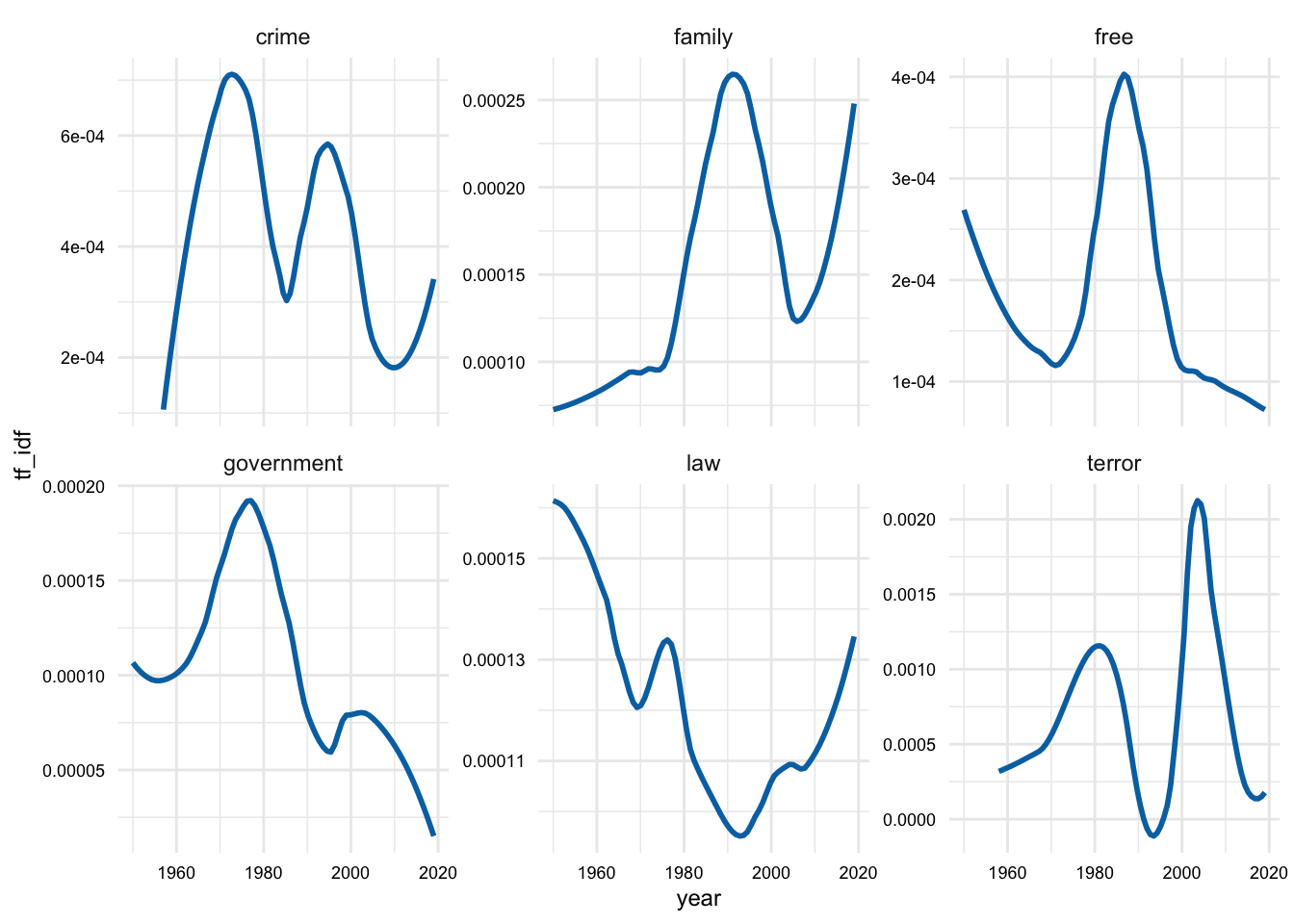
Figure @ref(fig:sotu-terms-tfidf-df-political-smooth-detail) seems to be picking up on some of the more general word usage trends over time.
Another thing to note about the way we plotted the data is that we used the facet_wrap() function to create a separate plot for each word but we used the scales = "free_y" allowing the y-axis to vary for each plot. This means we are not comparing the y-axis values across plots and thus can not say anything about the differing magnitudes from a visual inspection.
To address this, we can remove the scales = "free_y" argument and use the default which will fix the x- and y-axis scales across plots.
sotu_terms_tfidf_df |>
filter(lemma %in% plot_terms) |>
ggplot(aes(year, tf_idf)) +
geom_smooth(se = FALSE, span = 0.5) +
facet_wrap(~lemma)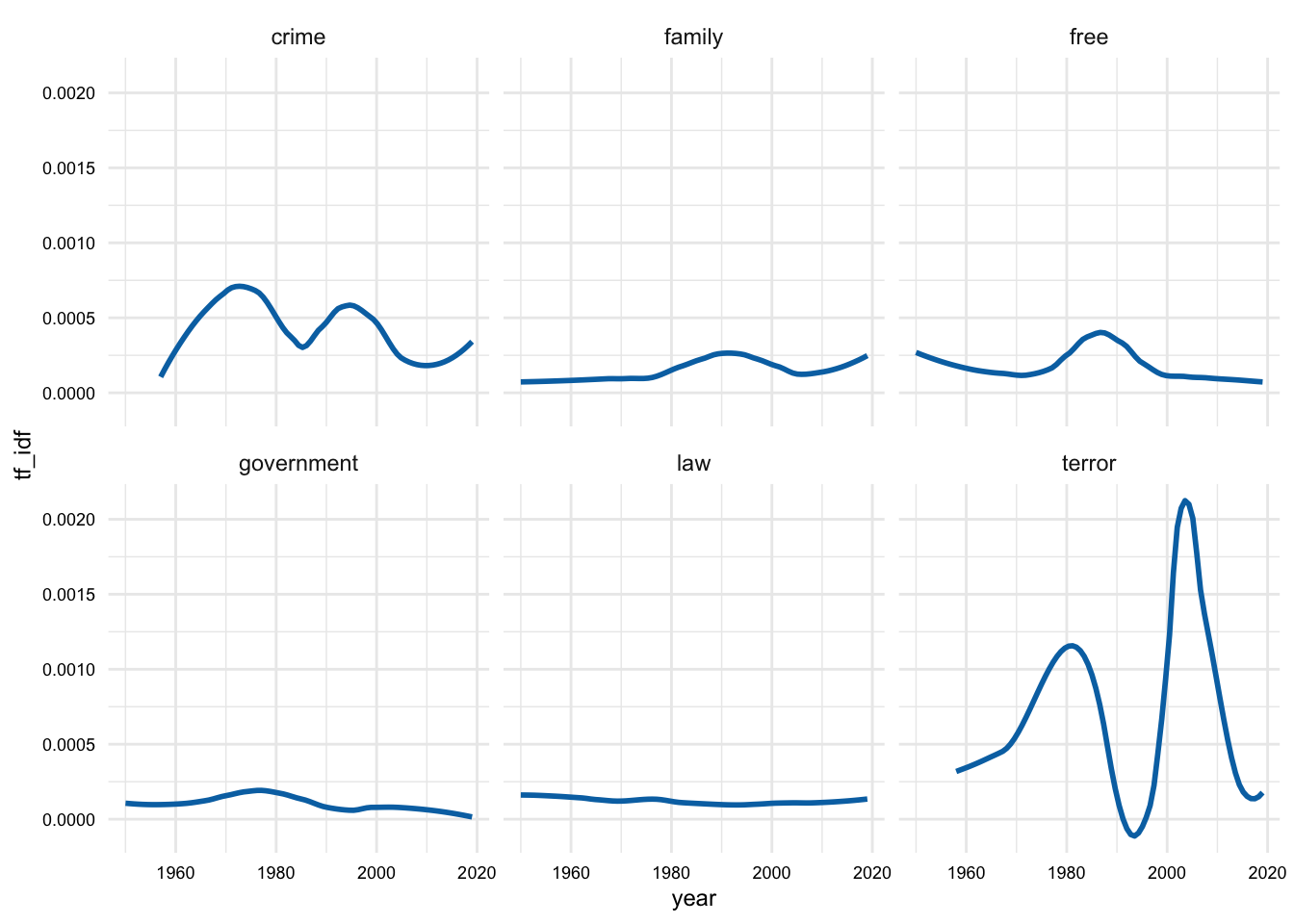
In Figure 7, we can clearly see that the magnitude of the words “crime” and “terror” are much higher than the other words we happend to select. Furthermore, these words have interesting patterns. In particular, “terror” has two peaks on around 1980 and another around the turn of the century. “Crime” also has two distinctive peaks on in the 1970s and one in the 1990s.
The terms that I selected before were somewhat arbitrary. How can I identify the words that have changed the most drastically over these years from the data itself? We can do this by creating a term-document matrix with and then calculating the standard deviation of the \(tf\)-\(idf\) values for each word. This will give us a sense of the words that have changed the most over time.
# Create TDM with words-year and tf-idf values
sotu_word_tfidf_mat <-
sotu_terms_tfidf_df |>
cast_tdm(word, year, tf_idf) |>
as.matrix()
# Preview
dim(sotu_word_tfidf_mat)[1] 13109 69sotu_word_tfidf_mat[1:5, 1:5] Docs
Terms 1950 1951 1952 1953 1954
enjoyment 0.00207 0.00000 0.000661 0 0
rent 0.00167 0.00000 0.000000 0 0
widespread 0.00167 0.00000 0.000000 0 0
underdeveloped 0.00165 0.00000 0.000000 0 0
ideals 0.00156 0.00171 0.000853 0 0To calculate the standard deviation of the \(tf\)-\(idf\) values for each word, we can use the apply() function to iterate over each row of the matrix and calculate the standard deviation of the values in each row. You can think of the apply() function as a cousin of the map() function. The apply() function iterates over the rows or columns of a matrix or data frame and applies a function to each row or column. We choose whether the function is applied to the rows or columns with the MARGIN argument. We can set MARGIN = 1 to apply the function to the rows and MARGIN = 2 to apply the function to the columns.
# Calculate the standard deviation of the tf-idf values for each word
sotu_words_sd <-
apply(sotu_word_tfidf_mat, MARGIN = 1, FUN = sd, na.rm = TRUE)
# Preview seed words
sotu_words_sd |>
sort(decreasing = TRUE) |>
head(100) vietnam hussein saddam salt iraq shall
0.001188 0.001138 0.001121 0.001067 0.000976 0.000887
oil iraqi that's inspectors qaida terror
0.000798 0.000786 0.000733 0.000715 0.000702 0.000662
terrorists it's crude soviet terrorist activity
0.000651 0.000647 0.000635 0.000633 0.000632 0.000630
covenant arrangements session al disarmament steven
0.000611 0.000609 0.000596 0.000596 0.000589 0.000588
wartime barrels isil mentioned ought elvin
0.000573 0.000569 0.000567 0.000559 0.000558 0.000556
iraqis ryan we're kids let's gun
0.000551 0.000539 0.000539 0.000535 0.000533 0.000532
rebekah cj camps empower cory we've
0.000531 0.000527 0.000524 0.000523 0.000522 0.000518
92d afghanistan childcare 100th music gulf
0.000516 0.000514 0.000513 0.000507 0.000500 0.000494
21st extremists foundation picture beguiled contemplate
0.000491 0.000489 0.000487 0.000486 0.000473 0.000473
enumerate hurriedly hysterical ingredients smile smiles
0.000473 0.000473 0.000473 0.000473 0.000473 0.000473
wagehour josefina shi'a alice alliance seventies
0.000473 0.000471 0.000468 0.000468 0.000467 0.000464
herman joshua matthew julie 11th border
0.000463 0.000463 0.000463 0.000462 0.000461 0.000459
persian recommend communist mayor nicaragua planes
0.000456 0.000453 0.000447 0.000443 0.000442 0.000442
trevor corey kenton preston seong property
0.000440 0.000439 0.000439 0.000439 0.000439 0.000439
regimes disarm mention peacetime localities objective
0.000437 0.000436 0.000436 0.000433 0.000429 0.000428
i'm surtax banks pounds foster she
0.000424 0.000423 0.000423 0.000422 0.000421 0.000418
isis sandinistas discharging gold
0.000417 0.000416 0.000416 0.000415 Now we can choose from the top words that have changed the most over time. Here’s another selection of words based on the standard deviation of the \(tf\)-\(idf\) values.
plot_terms <- c("equality", "right", "community", "child", "woman", "man")
sotu_terms_tfidf_df |>
filter(lemma %in% plot_terms) |>
ggplot(aes(year, tf_idf)) +
geom_smooth(se = FALSE, span = 0.5) +
geom_smooth(method = "lm") +
facet_wrap(~lemma)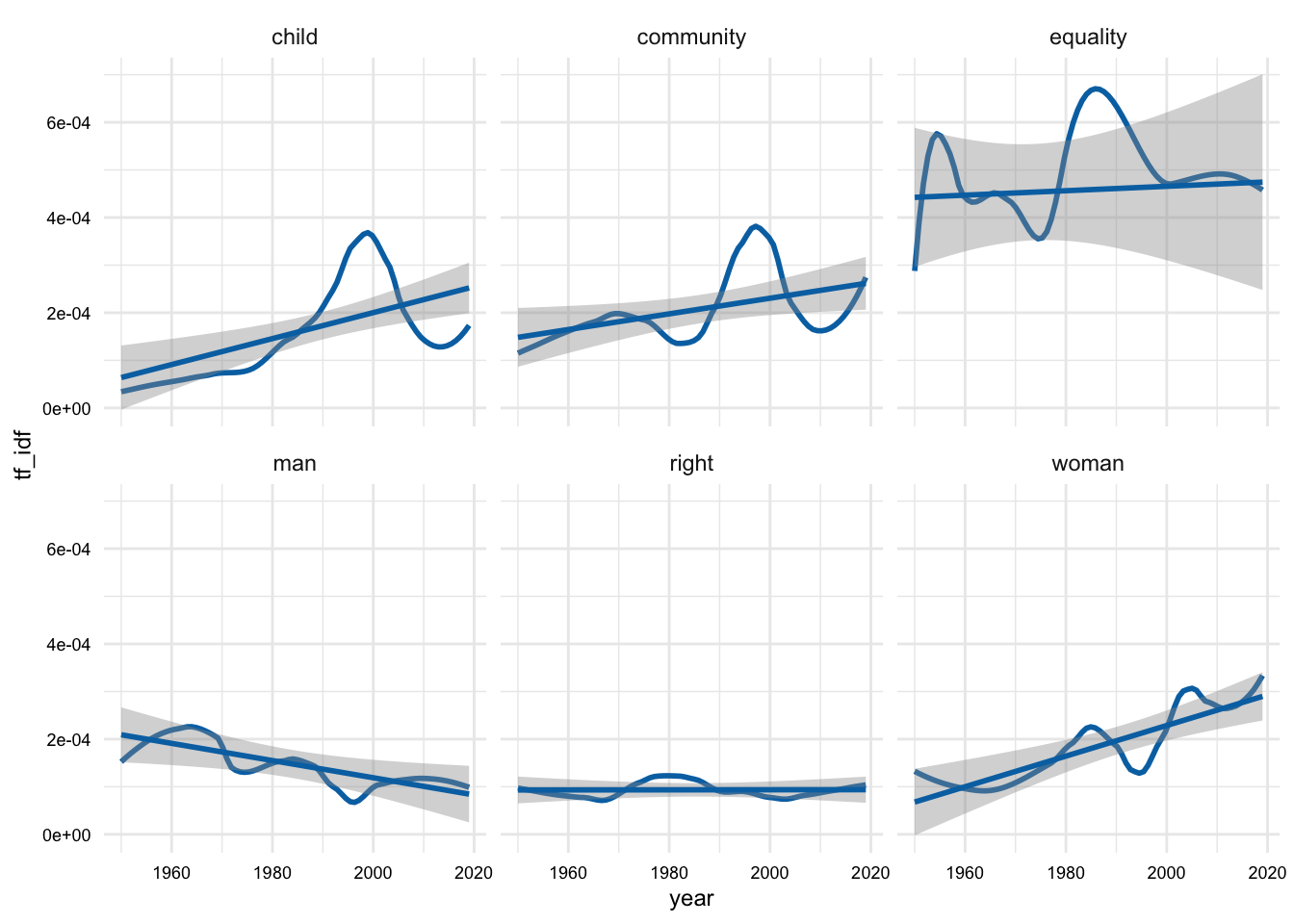
We can see that the words I selected based on the standard deviation, in Figure 8, can either increase, decrease, or fluctuate over time.
Meaning
- How does the meaning of words change across time periods?
For this approach we need to turn to word embeddings. Word embeddings have been show to capture distributional semantics –that is the meaning of words based on their distribution in a corpus (Hamilton, Leskovec, and Jurafsky 2016).
Since our research question is aimed a change over time we are performing a diachronic analysis. This means that we will need to create word embeddings for each time period, identify the common vocabulary across time periods, and then align the word embeddings to a common space before we can compare them.
Let’s load some packages that we will need.
library(fs) # for file system functions
library(PsychWordVec) # for working with word embeddings
library(purrr) # for iterating over listsLet’s first start by creating sub-corpora for each decade. We will write these to disk so that we can use them again if necessary. Note that data or datasets that are generated in the process of analysis are often stored in an analysis/ folder inside of the main data folder to keep them separate from the other data acquired or derived in the project.
We will use the str_c() function to summarize the words for each address into a single string by decade. We will then use the write_lines() function to write the string to a text file. The pwalk() function from {purrr} is a convenient way to iterate over multiple arguments (decade and address in this case) in a function without returning a value to the console. The p in pwalk() stands for “parallel” and indicates that the function will iterate over the arguments in parallel.
# Create sub-corpora for each decade and write to disk ------------
sotu_terms_df |>
summarize(address = str_c(lemma, collapse = " "), .by = decade) |>
select(decade, address) |>
pwalk(\(decade, address) {
file_name <- str_c("../data/analysis/sotu/", decade, "s.txt")
write_lines(address, file_name)
})Now I have written a function to read the text files, train the word embeddings for each, write the word embeddings to disk, and then load them back as VectorSpaceModel objects in a list.
create_embeddings <- function(dir_path, dims = 100) {
# Get the text file paths
txt_files <- dir_ls(dir_path, regexp = "\\.txt$")
# Train the word embeddings
models <-
txt_files |>
map(\(file) {
train_wordvec(
text = file,
dims = 100,
normalize = TRUE
)
})
# Modify the list names
names(models) <-
names(models) |>
basename() |>
str_remove("\\.txt")
# Convert to embed matrices
models <- map(models, as_embed)
return(models)
}We can now apply the create_embeddings() custom function to the decade sub-corpora text files in ../analysis/sotu/.
sotu_vec_mods <- create_embeddings("../analysis/sotu/")Each word embedding model is a matrix with the words as the rows and the dimensions as the columns as an element of the sotu_vec_mods list. Each of these elements have the name of the decade. We can extract an element from a list using the pluck() function from {purrr}.
# Extract an element from a list
sotu_vec_mods |> pluck("1950s") dim1 ... dim100
1: the 0.2910 ... <100 dims>
2: of 0.2229 ... <100 dims>
3: and 0.2818 ... <100 dims>
4: be 0.1370 ... <100 dims>
5: to 0.2336 ... <100 dims>
-----
1164: appear 0.2471 ... <100 dims>
1165: allegiance 0.2689 ... <100 dims>
1166: accumulate 0.2158 ... <100 dims>
1167: accomplishment 0.2241 ... <100 dims>
1168: accept 0.2440 ... <100 dims>These embeddings can be explored in a number of ways. For example, we can get the words closest to a given word in the vector space for each decade. {PsychWordVec} has a function, most_similar(), that will do this for us. We can use the map() function to iterate over each model in the list and get the words with the most similar vectors. We will then use the str_c() function to summarize the words into a single string for each decade.
# Get the closest words
sotu_vec_mods |>
map(\(mod) {
most_similar(mod, "freedom", verbose = FALSE) # get words similar to "freedom"
}) |>
map(\(res) {
str_c(res$word, collapse = ", ") # summarize the words into a single string
})$`1950s`
[1] "justice, peace, man, not, spirit, ideal, peaceful, fight, us, preserve"
$`1960s`
[1] "free, unity, berlin, asia, independence, course, communist, nation, europe, both"
$`1970s`
[1] "defend, close, destroy, found, shape, side, deter, honor, root, international"
$`1980s`
[1] "democracy, peace, struggle, defend, everywhere, democratic, secure, country, fighter, free"
$`1990s`
[1] "liberty, define, all, lead, perfect, share, force, communism, shape, latin"
$`2000s`
[1] "east, democracy, friend, liberty, woman, determine, military, middle, region, remain"
$`2010s`
[1] "heart, vision, remind, hero, hopeful, dignity, capitol, celebrate, journey, honor"The previous example shows that the closest words to “freedom” in each decade in a synchronic manner. We can inspect these synchronic changes and draw conclusions from them. However, we are interested in diachronic changes. To do this, we will need to align the word embeddings to a common space.
Now we will identify the common words across the decades and subset the word embeddings to the common vocabulary. The map() function iterates over each model in the list and returns the rownames with rownames() (words) for each model. The reduce() function then iterates over the list of words and returns the intersection of the words across the models with intersect().
# Extract the common vocabulary -----------------------------------
common_vocab <-
sotu_vec_mods |>
map(rownames) |>
reduce(intersect)
length(common_vocab)[1] 534head(common_vocab)[1] "the" "of" "and" "be" "to" "in" There are 534 words in the common vocabulary. Now we can subset the word embeddings to the common vocabulary. We will use the map() function to iterate over each model in the list and subset the model to the common vocabulary using the common_vocab variable as part of the bracket notation subset.
# Subset the models to the common vocabulary ----------------------
sotu_vec_common_mods <-
sotu_vec_mods |>
map(\(mod) {
mod[common_vocab, ] # subset each model to the common vocabulary
})
sotu_vec_common_mods |> pluck("1950s") dim1 ... dim100
1: the 0.2910 ... <100 dims>
2: of 0.2229 ... <100 dims>
3: and 0.2818 ... <100 dims>
4: be 0.1370 ... <100 dims>
5: to 0.2336 ... <100 dims>
----
530: happen 0.2186 ... <100 dims>
531: everything 0.2229 ... <100 dims>
532: different 0.2373 ... <100 dims>
533: debate 0.2244 ... <100 dims>
534: city 0.2320 ... <100 dims>sotu_vec_common_mods |> pluck("2010s") dim1 ... dim100
1: the -0.1464 ... <100 dims>
2: of -0.1187 ... <100 dims>
3: and -0.1090 ... <100 dims>
4: be -0.1162 ... <100 dims>
5: to -0.0842 ... <100 dims>
----
530: happen -0.1037 ... <100 dims>
531: everything -0.0982 ... <100 dims>
532: different -0.1032 ... <100 dims>
533: debate -0.1111 ... <100 dims>
534: city -0.1179 ... <100 dims>So now each of the models in the list has the same vocabulary and the same number of dimensions, 100.
Now we can align the models to a common space. The reason that the models need to be aligned is that the word embeddings are trained on different corpora. This means that the words will be represented in different spaces. We will use the Orthogonal Procrustes solution to align the models to a common coordinate space. {PsychWordVec} (Bao 2023) has a function, orth_procrustes(), that will do this for us. In the process of aligning the models, the models are converted to plain matrices so we will need to convert them back to embed matrix objects.
# Align the models to a common space
sotu_aligned_mods <-
sotu_vec_common_mods |>
map(\(mod) {
orth_procrustes(sotu_vec_common_mods[[1]], mod) # align to the first model
}) |>
map(\(mod) {
emb <- as_embed(mod) # convert to a embed matrix object
emb
})Having a model for each decade which is aligned in vocabulary and space, we can now use these models to compare words across time. There are a number of ways we can compare words across time.
In our first approach, let’s consider the semantic displacement of words over time in the vector space. We will do this by calculating the cosine difference between the word embeddings for a word in each decade. Once we have the cosine difference, we can visualize the change over time.
# Calculate the cosine difference between the models --------------
word <- "freedom"
word_vectors <-
sotu_aligned_mods |>
map(\(mod) {
mod[word, ]
})
differences <-
word_vectors |>
map(\(vec) {
cos_dist(vec, word_vectors[[1]])
})
differences$`1950s`
[1] 0
$`1960s`
[1] 0.0236
$`1970s`
[1] 0.0437
$`1980s`
[1] 0.0354
$`1990s`
[1] 0.0203
$`2000s`
[1] 0.0207
$`2010s`
[1] 0.0333We now have a list with the cosine difference for each decade compared to the first decade (“1950s”). We can visualize this with a line plot where the x-axis is the decade and the y-axis is the cosine difference. We will add a linear trend line to the plot to get a sense of the overall trend.
I’ll write a function to get the differences for a word and then return a data frame with the decade and the difference. This will make it easier to visualize the differences for multiple words.
# Function to get the cosine difference over time
get_cosine_diff <- function(word, models) {
word_vectors <- map(models, \(mod) {
mod[word, ]
})
differences <- map(word_vectors, \(vec) {
cos_dist(vec, word_vectors[[1]])
})
tibble(word, decade = basename(names(differences)), difference = unlist(differences))
}
get_cosine_diff(word = "freedom", models = sotu_aligned_mods)# A tibble: 7 × 3
word decade difference
<chr> <chr> <dbl>
1 freedom 1950s 0
2 freedom 1960s 0.0236
3 freedom 1970s 0.0437
4 freedom 1980s 0.0354
5 freedom 1990s 0.0203
6 freedom 2000s 0.0207
7 freedom 2010s 0.0333Let’s create a function which performs this for us and can plot multiple words at the same time.
plot_words <-
c("freedom", "nation", "country", "america")
plot_words |>
map(get_cosine_diff, models = sotu_aligned_mods) |>
bind_rows() |>
arrange(decade) |>
ggplot(aes(decade, difference, group = word, color = word)) +
geom_smooth(se = FALSE, span = 1) +
labs(title = word)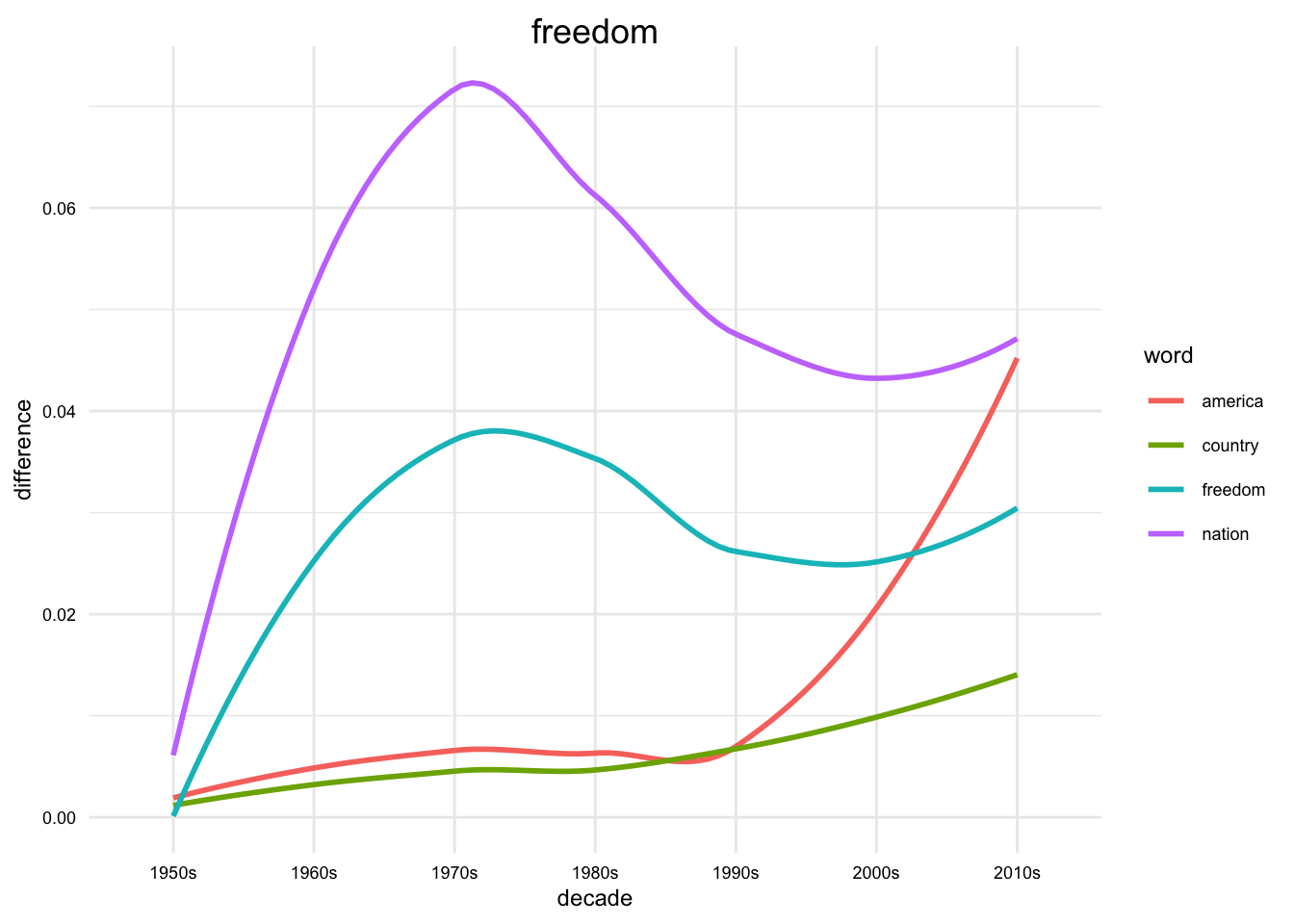
We can then focus in on a particular word and the nearest words to that word in each decade. We will use the map() function to iterate over each model in the list and get the closest words to a word. We will then use the str_c() function to summarize the words into a single string for each decade.
# Function to get the closest words to a word ---------------------
word <- "america"
sotu_vec_common_mods |>
map(\(mod) {
most_similar(mod, word, verbose = FALSE)
}) |>
map(\(mod) {
str_c(mod$word, collapse = ", ")
}) |>
enframe(name = "decade", value = "words") |>
unnest(words)# A tibble: 7 × 2
decade words
<chr> <chr>
1 1950s people, upon, life, democracy, standard, american, fail, within, deep,…
2 1960s leadership, agency, whole, serious, basic, historic, respect, responsi…
3 1970s where, liberty, determine, future, faith, happen, always, achieve, tru…
4 1980s never, great, let, ready, nation, faith, future, we, hope, struggle
5 1990s liberty, freedom, important, duty, moment, arm, ahead, great, always, …
6 2000s remember, common, moment, first, rest, sense, beyond, share, reach, ch…
7 2010s strong, state, once, may, believe, union, your, among, citizen, forwardAnother approach is to visualize the vector space that words occupy over time. To do this we will collapse the word embeddings for each decade into a single matrix. We will append the decade to each word as not to lose the decade information. The we will extract the first two principal components of the matrix, so that we can visualize the data in two dimensions. We will then plot the data with a scatter plot where the x-axis is the first principal component and the y-axis is the second principal component. We will label the points with the words.
# Visualize the vector space of words over time -------------------
sotu_joined_mods <-
sotu_aligned_mods |>
imap(\(mod, index) {
rownames(mod) <- str_c(rownames(mod), "_", index)
mod
}) |>
reduce(rbind) |>
as_embed()PCA on the word embeddings, yes! With the aligned models the results are much more sensible and interesting. The individual words are grouped closer together across time, in general, but there are exceptions.
sotu_joined_pca <-
sotu_joined_mods |>
scale() |>
prcomp()
sotu_pca_df <-
as_tibble(sotu_joined_pca$x[, 1:2]) |>
mutate(word = names(sotu_joined_pca$x[, 1]))
sotu_pca_df |>
filter(str_detect(word, "^(nation|country|america)_")) |>
ggplot(aes(x = PC1, y = PC2, label = word)) +
geom_point() +
ggrepel::geom_text_repel()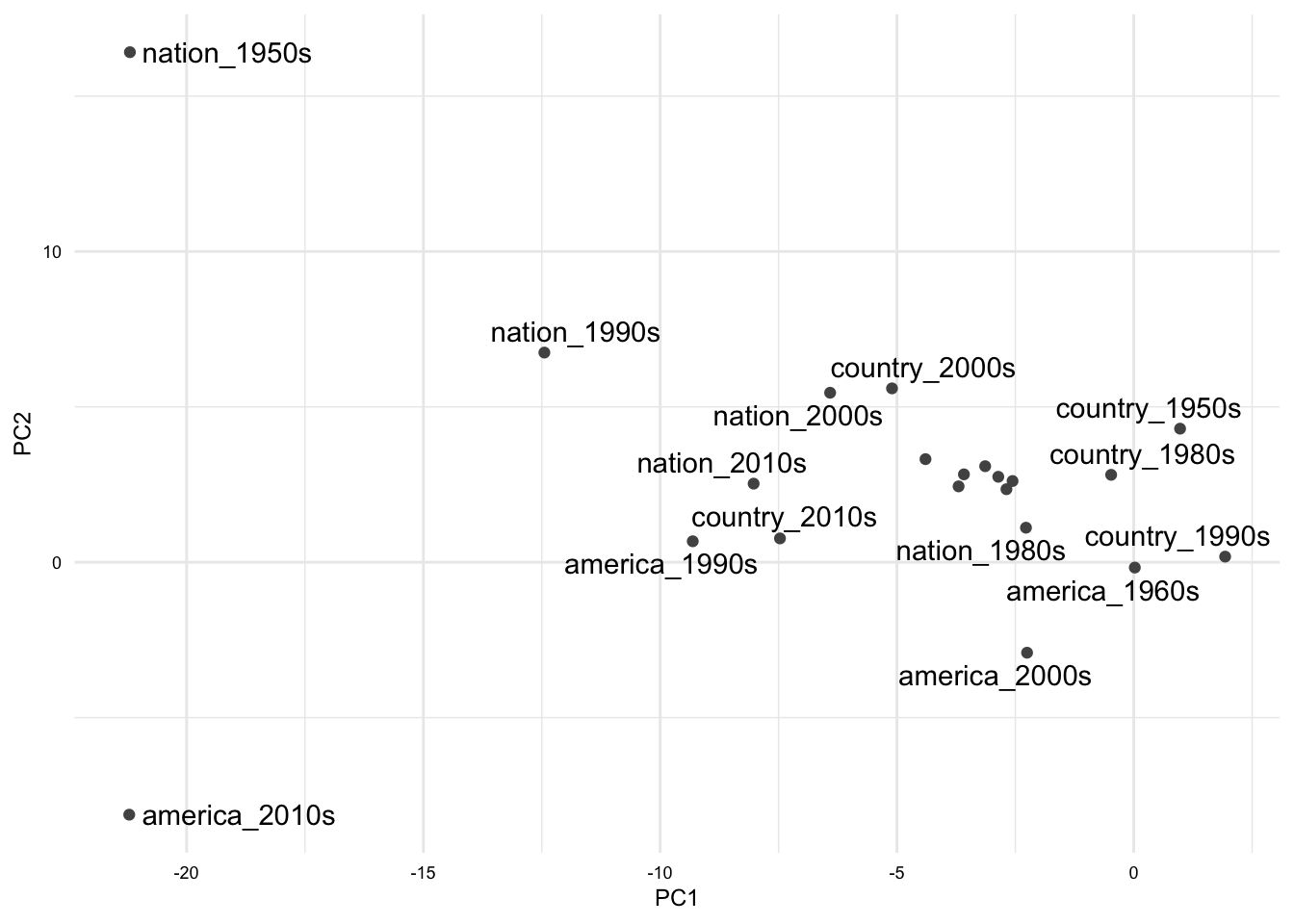
These kinds of visualizations can be very useful for exploring the data and drawing conclusions.
Summary
In this recipe, we have explored the State of the Union addresses from 1950 to 2019. We have used a number of tools and techniques to explore the data and draw conclusions. We have used {tidytext} to tokenize and lemmatize the words in the addresses. We have used {word2vec} to train word embeddings for each decade. We have used {PsychWordVec} to align the word embeddings to a common space. We have used {wordVectors} to explore the word embeddings. We have used {ggplot2} to visualize the data.
These strategies, and others, can be used to explore these questions or other questions in more depth. Exploratory analysis is where your creativity and curiosity can shine.
Check your understanding
- In text analysis, is used to transform the effect of words that are common across all time periods and promote the effect of words that are more distinctive to each time period.
- What is the correct method to use when adding a linear trend line to a plot in ggplot2?
- When working with lists,
walk()is likemap()but does not return a value. - When creating word embeddings, the CBOW model is better suited for less common words and smaller datasets compared to Skip-gram.
- The process of reducing the number of features in a dataset while retaining as much information as possible is known as reduction.
Lab preparation
In preparation for Lab 8, review and and ensure that you are familiar with the following concepts:
- Tokenizing text
- Generating frequency and dispersion measures
- Creating Term-Document Matrices
- Using {purrr} to iterate over lists
- Visualizations with {ggplot2}
In this lab, you will have the opportunity to apply the concepts from the materials in this chapter to a new dataset. You should consider the dataset and the questions that you want to ask of the data. You should also consider the tools and techniques that you will use to explore the data and draw conclusions. You will be asked to submit your code and a brief report of your findings.
References
Bao, Han-Wu-Shuang. 2023. PsychWordVec: Word Embedding Research Framework for Psychological Science. https://psychbruce.github.io/PsychWordVec/.
Hamilton, William L., Jure Leskovec, and Daniel Jurafsky. 2016. “Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change.” In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 1489–1501.