# A function that takes a name and returns a greeting
greetings <- function(name) {
paste("Hello", name)
}
# Apply function to a name
greetings(name = "R user")[1] "Hello R user"The purpose of this preface is to present the rationale behind this textbook, outline the key learning objectives, describe the pedagogical approach, and identify the intended audience. Additionally, this chapter will provide readers with a guide to the book’s structure and the scope of its content, as well as a summary of supporting learning and instructor resources. Finally, this chapter will provide readers with information on setting up their computing environment and where to seek support.
Data science, an interdisciplinary field that combines knowledge and skills from statistics, computer science, and domain-specific expertise to extract meaningful insight from structured and unstructured data, has emerged as an exciting and rapidly growing field in recent years, driven in large part by the increase in computing power available to the average individual and the abundance of electronic data now available through the internet. These advances have become an integral part of the modern scientific landscape, with data-driven insights now being used to inform decision-making in a wide variety of academic fields, including linguistics and language-related disciplines.
This textbook seeks to meet this growing demand by providing an introduction to the fundamental concepts and practical programming skills from data science applied to the task of quantitative text analysis. It is intended primarily for undergraduate students, but may also be useful for graduates and researchers seeking to expand their methodological toolbox. The textbook takes a pedagogical approach which assumes no prior experience with statistics or programming, making it an accessible resource for novices beginning their exploration of quantitative text analysis methods.
The overarching goal of this textbook is to provide readers with foundational knowledge and practical skills to conduct and evaluate quantitative text analysis using the R programming language and other open source tools and technologies. The specific aims are to develop the reader’s proficiency in three main areas:
Data literacy: Identify, interpret and evaluate data analysis procedures and results.
Throughout this textbook we will explore topics which will help you understand how data analysis methods derive insight from data. In this process you will be encouraged to critically evaluate connections across linguistic and language-related disciplines using data analysis knowledge and skills. Data literacy is an invaluable skillset for academics and professionals but also is indispensable for 21st-century citizens to navigate and actively participate in the “Information Age” in which we live (Carmi, Yates, Lockley, & Pawluczuk, 2020).
Research skills: Design, implement, and communicate quantitative text analysis research.
This aim does not differ significantly, in spirit, from common learning outcomes in a research methods course. However, working with text will incur a series of key steps in the selection, collection, and preparation of the data that are unique to text analysis projects. In addition, I will stress the importance of research documentation and creating reproducible research as an integral part of modern scientific inquiry (Buckheit & Donoho, 1995).
Programming skills: Develop and apply programming skills to text analysis tasks in a reproducible manner.
Modern data analysis, and by extension, text analysis is conducted using programming. There are various key reasons for this: a programming approach (1) affords researchers unlimited research freedom —if you can envision it, you can program it, (2) underlies well-documented and reproducible research (Gandrud, 2015), and (3) invites researchers to engage more intimately with the data and the methods for analysis.
These aims are important for linguistics students because they provide a foundation for concepts and in the skills required to succeed in the rapidly evolving landscape of 21st-century research. These abilities enable researchers to evaluate and conduct high-quality empirical investigation across linguistic fields on a wide variety of topics. Moreover, these skills go beyond linguistics research; they are widely applicable across many disciplines where quantitative data analysis and programming are becoming increasingly important. Thus, this textbook provides students with a comprehensive introduction to quantitative text analysis that is relevant to linguistics research and that equips them with valuable skills for their future careers.
The approach taken in this textbook is designed to accommodate linguistics students and researchers with little to no prior experience with programming or quantitative methods. With this in mind the objective is connect conceptual understanding with practical application. Real-world data and research tasks relevant to linguistics are used throughout the book to provide context and to motivate the learning process1. Furthermore, as an introduction to the field, the textbook focuses on the most common and fundamental methods and techniques for quantitative text analysis and prioritizes breadth over depth and intuitive understanding over technical explanations. On the programming side, the Tidyverse approach to programming in will be adopted (Wickham, 2014). This approach provides a consistent syntax across different packages and is known for its legibility, making it easier for readers to understand and write code. Together, these strategies form an approach that is intended to provide readers with an accessible resource to gain a foothold in the field and to equip them with the knowledge and skills to apply quantitative text analysis in their own research.
The aims and approach described above are reflected in the overall structure of the book and each chapter.
At the book level, there are five interdependent parts:
Part I “Orientation” provides the necessary background knowledge to situate quantitative text analysis in the wider context of data analysis and linguistic research and to provide a clearer picture of what text analysis entails and its range of applications.
The subsequent parts are directly aligned with the data analysis process. The building blocks of this process are reflected in ‘Data to Insight Hierarchy (DIKI)’ visualized in Figure 1.
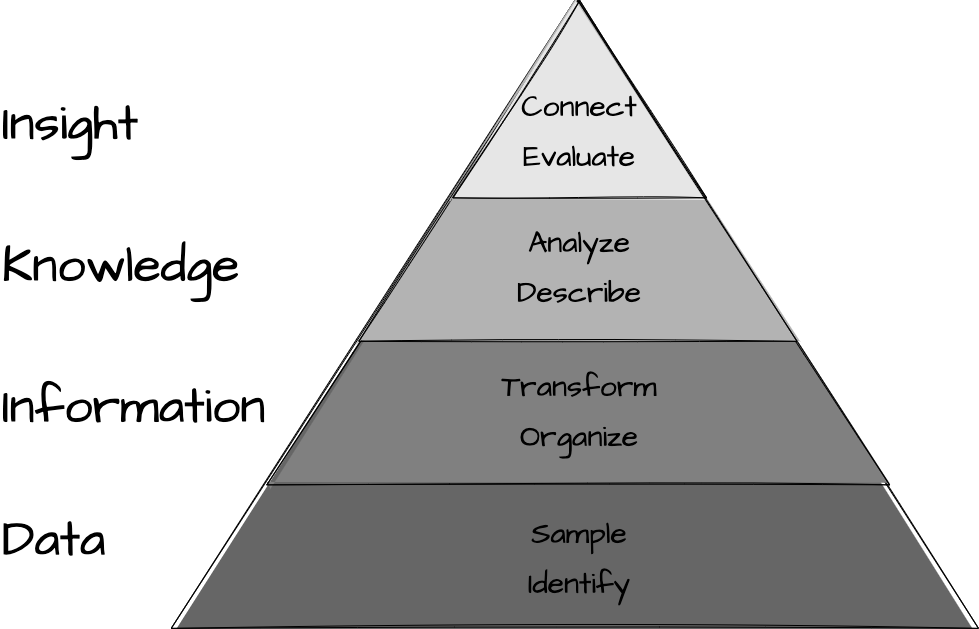
The DIKI Hierarchy highlights the stages and intermediate steps required to derive insight from data. Part II “Foundations” provides a conceptual introduction to the DIKI Hierarchy and establishes foundational knowledge about data, information, knowledge, and insight which is fundamental to developing a viable research plan.
Parts III “Preparation” and IV “Analysis” focus on the implementation process. Part III covers the steps involved in preparing data for analysis, including data acquisition, curation, and transformation. Part IV covers the steps involved in conducting analysis, including exploratory, predictive, and inferential data analysis.
The final part, Part V “Communication”, covers the final stage of the data analysis process, which is to communicate the results of the analysis. This includes the structure and content of research reports as well as the process of publishing, sharing, and collaborating on research.
At the chapter level, both conceptual and programming skills are developed in stages3. The chapter-level structure is consistent across chapters and can be seen in Table 1.
| Component | Purpose | Resource | Stage |
|---|---|---|---|
| Outcomes | Identify the learning objectives for the chapter | Textbook | Indicate |
| Overview | Provide a brief introduction to the chapter topic | Textbook | Outline |
| Coding Lessons | Teach programming techniques with hands-on interactive exercises | GitHub | Interact |
| Content | Combine conceptual discussions and programming skills, incorporating thought-provoking questions, relevant studies, and advanced topic references | Textbook | Explore |
| Recipes | Offer step-by-step programming examples related to the chapter and relevant for the upcoming lab | Resources Kit | Examine |
| Labs | Allow readers to apply chapter-specific concepts and techniques to practical tasks | GitHub | Apply |
| Summary | Review the key concepts and skills covered in the chapter | Textbook | Review |
Each chapter will begin with a list of key learning outcomes followed by a brief introduction to the chapter’s content. The goal is to orient the reader to the chapter. Next there will be a prompt to complete the interactive coding lesson(s) to introduce readers to key programming concepts related to the chapter though hands-on experience and then the main content of the chapter will follow. The content will be a combination of conceptual discussions and programming skills, incorporating thought-provoking questions (‘ Consider this’), relevant studies (‘ Case study’), and advanced topic references (‘ Dive deeper’). Together these components form the skills and knowledge phase.
The next phase is the application phase. This phase will include step-by-step programming demonstrations related to the chapter (Recipes) and lab exercises that allow readers to apply their knowledge and skills to chapter-related tasks. Finally, the chapters conclude with a summary of the key concepts and skills covered in the chapter and in the associated activities.
The description and location of the available resources to support the aims and approach of this textbook appear in Table 2.
| Resource | Description | Location |
|---|---|---|
| Textbook | Prose discussion, figures/ tables, R code, case studies, and thought and practical exercises | Physical/ Web |
| {qtkit} | R package with functions for accessing data and datasets, as well as various useful functions developed specifically for this textbook | Web/ GitHub |
| Resources Kit | Includes Recipes, programming tutorials to enhance the reader’s recognition of how programming strategies are implemented, and other supplementary materials including setup Guides, and Instructor materials | Web/ GitHub |
| Lessons | A set of interactive R programming lessons associated with each chapter | GitHub |
| Labs | A set of lab exercises designed to direct the reader through practical hands-on programming applications | GitHub |
All resources are freely available and accessible to readers and are found on the GitHub organization https://github.com/qtalr/. For the textbook and Resources Kit, the code and a link to the website are provided in each respective repository. The development version of the {qtkit} package is available on GitHub and the stable version is available on the Comprehensive R Archive Network (CRAN) (Francom, 2024). The interactive programming lessons and lab exercises are also available on GitHub. Errata should be reported in the respective repository’s issue tracker on GitHub.
Before jumping in to this and subsequent chapter’s textbook activities, it is important to prepare your computing environment and understand how to take advantage of the resources available, both those directly and indirectly associated with the textbook.
Programming is the backbone for modern quantitative research. Among the many programming languages available, R is a popular open-source language and software environment for statistical computing. R is popular with statisticians and has been adopted as the de facto language by many other fields in natural and social sciences, including linguistics. It is freely downloadable from The R Project for Statistical Programming website (The R Foundation, 2024) and is available for macOS, Linux, and Windows operating systems.
Successfully installing R is rarely the last step in setting up your R-enabled computing environment. The majority of R users also install an integrated development environment (IDE). An IDE, such as RStudio (Posit, 2024), or a text editor, such as Visual Studio Code (Microsoft, 2024), provide a graphical user interface (GUI) for working with R4. In effect, these interfaces provide a dashboard for working with R and are designed to make it easier to write and execute R code. IDEs also provide a number of other useful features such as syntax highlighting, code completion, and debugging. IDEs are not required to work with R but they are highly recommended.
Choosing to install R and an IDE directly on your personal computer, which is know as your local environment, is not the only option to work with R. Other options include working with R in a remote environment or a virtual environment.
There are trade-offs in terms of cost, convenience, and flexibility when choosing to work with R in a local, remote, or virtual environment. The choice is yours and you can always change your mind later. The important thing is to get started and begin learning R. Furthermore, any of the approaches described here will be compatible with this textbook.
As you progress in your R programming experience, you’ll find yourself leveraging code from other R users, which is typically provided as packages. Packages are sets of functions and/or datasets that are freely accessible for download, designed to perform a specific set of interrelated tasks. They enhance the capabilities of R. Official R packages can be found in repositories like CRAN (R Community, 2024) or R-universe (ROpenSci, 2024), while other packages can be obtained from code-sharing platforms such as GitHub (GitHub, 2024).
You will download a number of packages at different stages of this textbook, but there is a set of packages that will be key to have from the get go. Once you have access to a working R environment, you can proceed to install the following packages.
Install the following packages from CRAN.
You can do this by running Example 1 in an R console:
Example 1
# install key packages from CRAN
install.packages(c("tidyverse", "tinytex", "swirl", "qtkit"))GitHub is a code sharing website. Modern computing is highly collaborative and GitHub is a very popular platform for sharing and collaborating on coding projects. The lab exercises for this textbook are shared on GitHub. To access and complete these exercises you will need to sign up for a (free) account and then set up the version control software Git on your computing environment.
The technologies employed in this approach to text analysis will include a somewhat steep learning curve. And in all honesty, the learning never stops! Both seasoned programmers and beginners alike need assistance. Fortunately, there is a very large community of programmers who have developed many official support resources and who actively contribute to official and unofficial discussion forums. Together these resources provide many avenues for overcoming challenges.
In Table 3, I provide a list of steps for seeking help with R.
| Step | Resource | Description |
|---|---|---|
| 1 | Official R Documentation | Access the official documentation by running help(package = "package_name") in an R console. Use the ? operator followed by the package or function name. Check out available Vignettes by running browseVignettes("package_name"). |
| 2 | Web Search | Look for package documentation and vignettes on the web. A popular site for this is R-Universe. |
| 3 | RStudio Help Toolbar | If you’re using RStudio, use the “Help” toolbar menu. It provides links to help resources, guides, and manuals. |
| 4 | Online Discussion Forums | Sites like Stack Overflow and RStudio Community are great platforms where the programming community asks and answers questions related to real-world issues. |
| 5 | Post Questions with Reprex | When posting a question, especially those involving coding issues or errors, provide enough background and include a reproducible example (reprex) —a minimal piece of code that demonstrates your issue. This helps others understand and answer your question effectively. |
The take-home message here is that you are not alone. There are many people world-wide that are learning to program and/or contribute to the learning of others. The more you engage with these resources and communities the more successful your learning will be. As soon as you are able, pay it forward. Posting questions and offering answers helps the community and engages and refines your skills —a win-win.
To facilitate the learning process, this textbook will employ a number of conventions. These conventions are intended to help the reader navigate the text and to signal the reader’s attention to important concepts and information.
The following typographic conventions are used throughout the text:
Fixed-width
More lengthy code will be presented in code blocks, as seen in Example 2.
Example 2
# A function that takes a name and returns a greeting
greetings <- function(name) {
paste("Hello", name)
}
# Apply function to a name
greetings(name = "R user")[1] "Hello R user"
There are a couple of things to note about the code in Example 2. First, it shows the code that is run in R as well as the output that is returned. The code will appear in a box and the output will appear below the box. Both code and output will appear in fixed-width font. Second, the # symbol within a code block is used to signal a code comment, a human-facing description. Everything right of a # is not run as code. In this textbook you will see code comments above code on a separate line and/or to the right of code on the same line. It is good practice to comment your code to enhance readability and to help others understand what your code is doing.
All figures, tables, and images in this textbook are generated by code blocks, but only code for those elements that are relevant for discussion will be shown. However, if you wish to see the code for any element in this textbook, you can visit the GitHub repository https://github.com/qtalr/book/.
When referencing a file or portion of a file, it will appear as in Snippet 1.
Callouts are used to signal the reader’s attention to content, activity, and other important sections. The following callouts are used in this textbook:
Content
Activities
Other
At this point you should have a working R environment with the core packages including {qtkit} installed. You should also have verified that you have a working Git environment and that you have a GitHub account. If you have not completed these tasks, return to the guides listed above in “Getting started” of this Preface and complete them before proceeding.
The following activities are designed to help you become familiar with the tools and resources that you will be using throughout this textbook. These and subsequent activities are designed to be completed in the order that they are presented in this textbook.
This preface outlines the textbook’s underlying principles, learning goals, teaching methods, and target audience. The chapter also offers advice on how to navigate the book’s layout, comprehend its subject matter, and make use of supplementary materials. With this foundation, you’re now prepared to dig into quantitative text analysis. I hope you enjoy the journey!
For recommendations on how to use this textbook in your course and to access additional resources, visit the Resources Kit “Instructor Guide”. The guide provides information on how to structure your course, how to use the textbook, and how to access additional resources to support your teaching.
Research data and questions are primarily based on English for wide accessibility as it is the de facto language of academics and research. However, the methods and techniques presented in this textbook are applicable to many other languages.↩︎
These stages attempt to capture the general progression of learning reflected in Bloom’s Taxonomy. See Krathwohl (2002) for a description and revised version.↩︎
For those who prefer a terminal-based text editor, Neovim is a popular choice. Neovim is a text editor that is designed to be extensible and customizable. It is a modern version of the classic Vim text editor.↩︎