11 Contribute
We have discussed the design and implementation of research that is purposive, inquisitive, informed, and methodical. In this final chapter, we turn to the task of sharing research results in a manner that is communicable. There are two primary ways to communicate the results of research: public-facing and peer-facing. We will cover both aspects of research communication, providing guidelines for effective research reporting and strategies to ensure the reproducibility of your research project.
11.1 Public-facing
Public-facing research communication is intended for audiences to become familiar with the research. Dissemination of research findings is a critical part of the research process. Whether it is through presentations, articles, blog posts, or social media, the ability to effectively communicate the results of research is essential for making a contribution to the field.
The two most common forms of research dissemination in academics are presentations and articles. Both share a common goal: to effectively communicate the research to an audience. However, they also have distinct purposes and require different approaches to achieve their goals. These purposes complement each other, with presentations often serving as a means to engage and elicit feedback from an audience, and articles serving as a more comprehensive and permanent record of the research.
Structure
First, let’s focus on the structural elements that appear in both research presentations and articles. The components in Table 11.1 reflect the typical structure for presenting research in the social sciences (Gries, 2016; Gries & Paquot, 2020; Sternberg & Sternberg, 2010). Their combined purpose is to trace the research narrative from the rationale and goals to connecting the findings with the research questions and aims.
| Component | Purpose |
|---|---|
| Introduction | Provide context and rationale based on previous research |
| Methods | Describe the research design and procedures |
| Results | Present the findings including key statistics and table and/or visual summaries |
| Discussion | Interpret the findings and discuss implications |
| Conclusion | Summarize the research and suggest future work |
When research is connected to a well-designed plan, as described in Chapter 4, key elements in this structure will have already begun to take shape. The steps taken to identify an area and a problem or gap in the literature find themselves in the introduction. This section builds the case for the research and provides the context for the research question(s) and aim(s). The methods section describes the research design and procedures, including the data collection and analysis steps that are key to contextualize the findings. In the results section, the findings are presented in the appropriate manner given the research aim and the analysis performed.
The discussion and conclusions sections, however, are where the research narrative is brought together. Crafting these sections can be seen as an extension of the research process itself. Instead of elaborating on the planning steps and their implementation, the discussion focuses on the interpretation of the findings in the light of the research questions and previous literature. At this stage, the act of articulating the implications of the findings is where deeper insights are developed and refined. The conclusion, for its part, puts a finer point on the research goal and main findings, but also is an opportunity to extend suggestions to where subsequent research might go.
Purpose
Understanding the roles the structural elements play in contributing to the overall narrative is essential for effective research communication. Yet, presentations and articles are not the same. They have distinct goals which are reflected in the emphasis that each communication channel places on particular narrative elements and the level of detail and nuance that is included.
It is likely not a surprise that articles are more detailed and nuanced than presentations. But what is sometimes overlooked is that presentations should emphasize storytelling and relatability. A ‘less is more’ approach can help maintain connection with the take-home message and reduce information overload. To be sure, the research should be accurate and reliable, but the focus is on engaging the audience and connecting the research to broader themes. Even if your audience is familiar with the research area, maintaining a connection with ‘why this matters’ is important.
Tabular and visual summaries are key to convey complex findings, regardless of the mode of communication. However, in presentations, the use of visual aids is especially effective for engaging the audience as the visual modality does not compete with the spoken word for attention. Along these lines, limiting the amount of text on slides and increasing natural discourse with the audience is a good practice. Your presentation will be more engaging leading to more questions and feedback that you can use to refine your current or to seed future research.
The purpose of an article is to provide a comprehensive record of the research. In this record, the methods and results sections are particularly significant. The methods section should provide the reader with the necessary information to understand the research design and procedures and to evaluate the findings, as it should in presentations, but, in contrast to presentations, it should also speak to researchers, providing the details required to reproduce the research. These details summarize and, ideally, point to the data and code that are used to produce the findings in your reproducible research project (see Section 11.2).
The results section, for its part, should present the findings in a manner that is clear and concise, but also comprehensive. The research aim and the analysis performed will determine the appropriate measures and/or summaries to use. Table 11.2 outlines the statistical results, tables, and visualizations that often figure in the results section for exploratory, predictive, and inferential analyses.
| Research Aim | Statistical Results | Summaries |
|---|---|---|
| Exploratory | Descriptive statistics | Extensive use of tables and/or visualizations |
| Predictive | Descriptive statistics, model performance metrics | Tables for model performance comparisons and/or visualizations for feature importance measures |
| Inferential | Descriptive statistics, hypothesis testing confidence metrics | Tables for hypothesis testing results and/or visualizations to visualize trends |
By and large, the results section should be a descriptive and visual summary of the findings as they are, without interpretation. The discussion section is where the interpretation of the findings and their implications are presented. This general distinction between the results and discussion may be less pronounced in exploratory research, as the interpretation of the findings may be more intertwined with the presentation of the findings given the nature of the research.
Strategies
Strong research write-ups begin with well-framed and well-documented research plans. The steps outlined in Section 4.4.1 are the foundation for much of the research narrative. Furthermore, you can further prepare for the research write-up by leaving yourself a breadcrumb trail during the research process. This includes documenting the literature that you consulted, the data, processing steps, and analysis choices that you made, and saving the key statistical results, tables, and visualizations that you generated in your process script for the analysis. This will make it easier to connect the research narrative to the research process.
The introduction includes the rationale, research question, and research aim. These components are directly connected to the primary literature that you consulted. For this reason, it is a good practice to keep a record of the literature that you consulted and the notes that you took. This record will help you to trace the development of your ideas and to provide the necessary context for your research. A reference manager, such as Zotero, Mendeley, or EndNote, is a good tool for this purpose. These tools allow you to manage your ideas and keep notes, organize your references and resources, and integrate your references and resources with your writing in Quarto through BibTeX entry citation keys.
Similarly, if you are following best practices, you will have documented your data, processing steps, and analysis choices while conducting your research. The methods section stems directly from these resources. Data origin files provide the necessary context for the data that you used in your research. Data dictionary files clarify variables and values in your datasets. Literate programming, as implemented in Quarto, can further provide process and analysis documentation.
The results section can also benefit from some preparation. The key statistical results, tables, and visualizations generated in your process script for the analysis should be saved as outputs. This provides a more convenient way to include these results in your research document(s).
If you are using a project structure similar to the one outlined in Section 4.4.2, you can write statistical results as R objects using saveRDS(), and write tables and visualizations as files using kableExtra::save_kable() and ggplot2::ggsave(), respectively, to the corresponding outputs/ directory. This will allow you to easily access and include these results in your research document(s) to avoid having to recreate the analysis steps from a dataset or manually copy and paste results from the console, which can be error-prone and is not reproducible.
At this point we have our ducks in a row, so to speak. We have a well-documented research plan, a record of the literature that we consulted, and a record of the data, processing steps, and analysis choices that we made. We have also saved the key statistical results, tables, and visualizations that we generated in our process script for the analysis. Now, we can begin to write our research document(s).
Although there are many tools and platforms for creating and sharing research presentations and articles, I advocate for using Quarto to create and share both. In Table 11.3, I outline the advantages of using Quarto for both presentations and articles.
| Feature | Advantages | |
|---|---|---|
| 1 | Consistency | Using Quarto for both presentations and articles allows for a seamless transition between the two |
| 2 | Fidelity | Changes in your research process will naturally be reflected in your write-ups |
| 3 | Sharing | Quarto provides a variety of output formats, including PDF, HTML, and Word, which are suitable for sharing research presentations and articles |
| 4 | Publishing | Quarto provides styles for citations and bibliographies and a variety of extensions for journal-specific formatting, which can be useful for publishing articles in specific venues |
Each of the features in Table 11.3 are individually useful, but together they provide a powerful system for conducting and disseminating research. In addition, Quarto encourages modular and reproducible research practices, which connect public-facing with peer-facing communication.
11.2 Peer-facing
Peer-facing communication targets other researchers, often working in same field, and aims to make the technical aspects of research available to other researchers to reproduce and/or build upon the research. Whether for other researchers or for your future self, creating research that is well-documented and reproducible is a fundamental part of conducting modern scientific inquiry. Reproducible research projects do not replace the need to document methods and results in write-ups, but they do provide a more comprehensive and transparent record of the research that elevates transparency, encourages collaboration, and enhances the visibility and impact of research.
Structure
Reproducible research consists of two main components: a research compendium and a computing environment. These components are interleaved and when shared, work together to ensure that the research project is transparent, well-documented, and reproducible.
Research compendium consists of a collection of files and documentation that organize and document a research project. This includes the data, code, and documentation files. To ensure that the project is legible and easy to navigate, the research compendium content and the project scaffolding should be predictable and consistent, following best practices outlined in Chapter 4 (4.4.2) and found in more detail in Wilson et al. (2017).
In short, there should be a separation between input, output, and the code that interacts with the input to produce the output. Furthermore, documentation for data, code, and the project as a whole should be clear and comprehensive. This includes a README file, a data origin file, and a data dictionary file, among others. Finally, a main script should be used to execute and coordinate the processing of the project steps.
All computational projects require a computing environment. This includes the software and hardware that are used to execute the code and process the data. For a text analysis project using R, this will include R and R packages. Regardless of the language, however, there are system-level dependencies, an operating system, and hardware resources that the project relies on.
Figure 11.1 visualizes the relationship between the computing environment and the research compendium as layers of a research environment. The research compendium is the top layer, each of the subsequent layers represents elements of the computing environment.
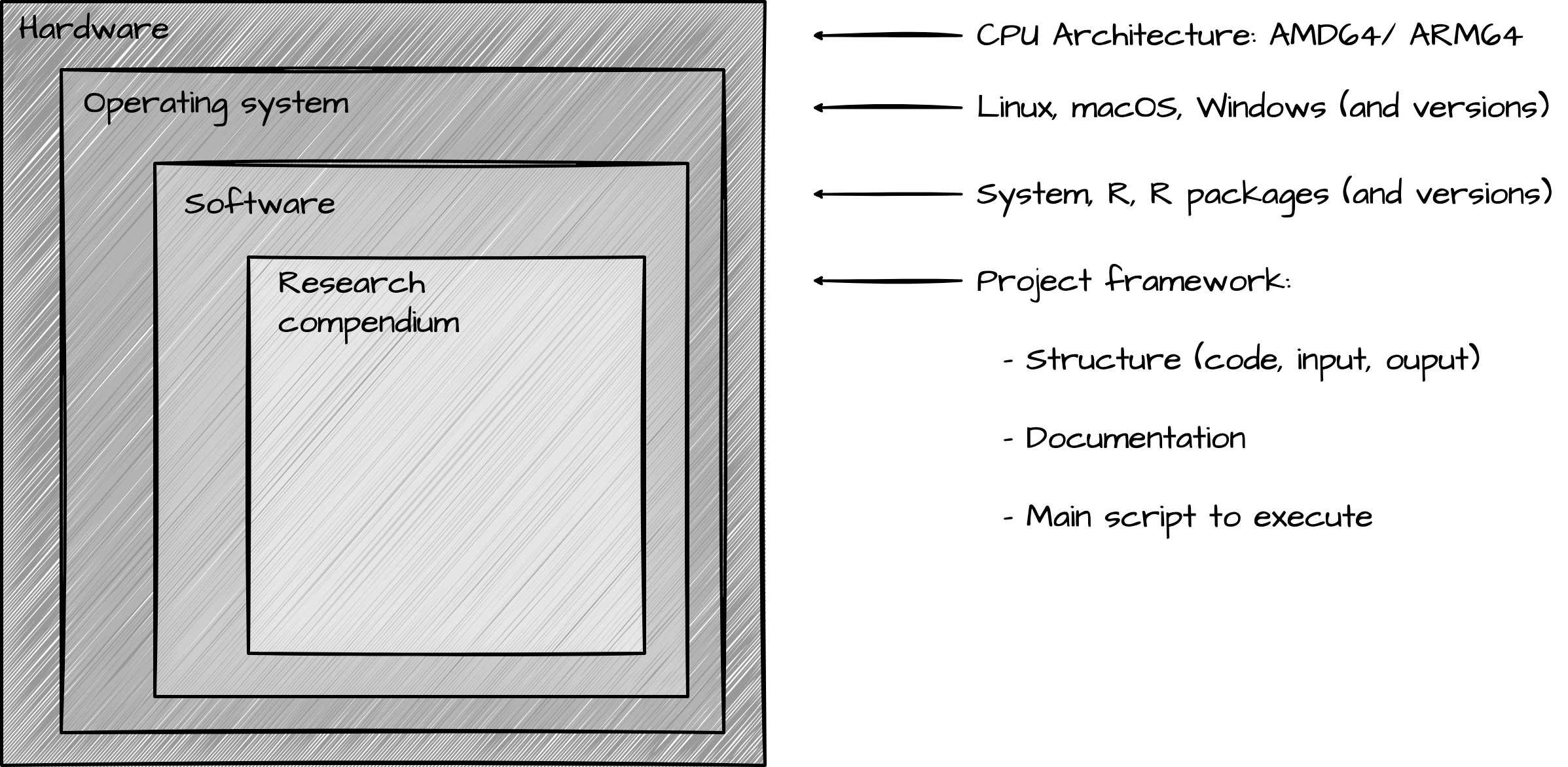
The research compendium is the most visible layer, as it is the primary means of interacting with the research project. The software layer includes R, R packages, and system-level dependencies. System-level dependencies serve to support the software layer. Software itself, these dependencies are not directly interacted with, but they are necessary for the more ‘visible’ software to function. Most people are familiar with operating systems, such as Windows, macOS, and perhaps Linux, but there are many different versions of these operating systems. Furthermore, hardware resources also vary. One of the most important aspects of hardware to consider for reproducibility is the architecture of the processor (the central processing unit (CPU)).
We will consider how to create a reproducible environment which addresses each of these layers later in this chapter.
Purpose
The research compendium is in large part a guide book to the research process. Efforts here increase research transparency, facilitate collaboration and peer review, and enhance the visibility and impact of research. It is also the case that keeping tabs on the process in this way helps to ensure that the research is accurate and reliable by encouraging you to be more mindful of the choices that you make and the steps that you take. Any research project is bound to have its share of false starts, dead ends, or logical lapses, but leaving a breadcrumb trail during the research process can help to make these more visible and help you (and others) learn from them.
The computing environment is a means to an end. It is the infrastructure that is used to execute the code. The purpose of the computing environment is to ensure that the research can be executed and processed in the same way, producing the same results, regardless of the time or place. While a research compendium has value on its own, the ability to add a level of ‘future-proofing’ to the project only adds to that value. This is both true for other researchers who might want to build upon your research and for yourself, as returning to a project after some time away can highlight how much computing environments can change when errors litter the screen!
Strategies
The strategies for creating a reproducible research project are many and varied, although that gap is closing as reproducible research moves from a nicety to a necessity in modern scientific research. In this section, I will present an opinionated set of strategies to address each of the layers of a computational research project seen in Figure 11.1, in a way that better positions research to be accessible to more people and to be more resilient to inevitable changes in the computing environment from machine to machine and over time.
A key component to research compendiums which integrate into a reproducible workflow is the use of a project structure that modularizes the research project into predictable and consistent components. This will primarily consist of input, output, and the code that executes and documents the processing steps. But it also consists of a coordinating script, that is used to orchestrate each module in the project step sequence.
A particularly effective framework for implementing a research compendium with these features is the Quarto website. Quarto documents, as literal programming is in general, provides rich support for integrating source content, computations, and visualizations in a single document. In addition, Quarto documents are designed to be modular —each is run in a separate R session making no assumptions about inputs or previous computing states. When tied to logical processing steps, this can help to ensure that each step says what it does, and does what it says, enhancing the transparency and reproducibility of the research project.
The Quarto website treats each document as part of a set of documents that are coordinated by a _quarto.yml configuration file. Rendering a Quarto website will execute and compile the Quarto documents as determined in the configuration settings. In this way, the goal of easy execution of the project is satisfied in a way that is consistent and predictable and co-opts a framework with wide support in the R community.
Creating the scaffolding for a research compendium in Quarto is a matter of creating a new Quarto website through an IDE, the R Console, or the command-line interface (CLI) and adding the necessary files, directories, and documentation. In Snippet 11.1 a Quarto site structure augmented to reflect the project structure is shown.
Snippet 11.1 Quarto website structure
project/
├── data/
│ └── ...
├── process/
│ ├── 1_acquire.qmd
│ ├── 2_curate.qmd
│ ├── 3_transform.qmd
│ └── 4_analyze.qmd
├── reports/
│ └── ...
├── _quarto.yml
├── DESCRIPTION
├── index.qmd
└── README.mdSnippet 11.2 shows a snippet of the _quarto.yml configuration file for a Quarto project website. This file is used to coordinate the Quarto documents in the project and to specify the output format for the project as a whole and for individual documents.
Snippet 11.2 Quarto _quarto.yml file
project:
title: "Project title"
type: website
render:
- index.qmd
- process/1_acquire.qmd
- process/2_curate.qmd
- process/3_transform.qmd
- process/4_analyze.qmd
- reports/
website:
sidebar:
contents:
- index.qmd
- section: "Process"
contents: process/*
- section: "Reports"
contents: reports/*
format:
html: defaultIn Snippet 11.2 the order in which each file is rendered can be specified to orchestrate the processing sequence. While the Quarto website as a whole will be rendered to HTML, individual documents can be rendered to other formats. This can be leveraged to create PDF versions of write-ups, for example, or use {revealjs} for Quarto to create presentations that are rendered and easily shared on the web. For ways to extend the Quarto website, visit the Quarto documentation at https://quarto.org/.
Let’s now turn to layers of the computing environment, starting with the portion of the software layer which includes R and R packages. R and R packages are updated, new packages are introduced, and some packages are removed from circulation. These changes are good overall, but it means that code we write today may not work in the future. It sure would be nice if we could keep the same versions of packages that worked for a project.
{renv} is a package that helps manage R package installation by versions (Ushey & Wickham, 2024). It does this by creating a separate environment for each R project where renv is initialized. This environment allows us to keep snapshots of the state of the project’s R environment in a lockfile —a file that contains the list of packages used in the project and their versions. This can be helpful for developing a project in a consistent environment and controlling what packages and package versions you use and update. More importantly, however, if the lockfile is shared with the project, it can be used to restore the project’s R environment to the state it was in when the lockfile was created, yet on a different machine or at a different time.
Adding a lockfile to a project is as simple as initializing renv in the project directory with renv::init() and running renv::snapshot(). Added to the project, in Snippet 11.1, we see the addition of the renv.lock file and the renv/ directory, in Snippet 11.3.
Snippet 11.3 Quarto website structure with {renv}
project/
├── data/
│ └── ...
├── process/
│ ├── 1_acquire.qmd
│ ├── 2_curate.qmd
│ ├── 3_transform.qmd
│ └── 4_analyze.qmd
├── reports/
│ └── ...
├── renv/
│ └── ...
├── _quarto.yml
├── index.qmd
├── README.md
└── renv.lockThe renv.lock file serves to document the computing environment and packages used to conduct the analysis. It therefore replaces the need for a DESCRIPTION file. The renv/ directory contains the R environment for the project. This includes a separate library for the project’s packages, and a cache for the packages that are installed. This directory is not shared with the project, as we will see, as the lockfile is sufficient to restore the project’s R environment.
As R packages change over time, so too do other resources including R, system dependencies, and the operating system —maybe less frequently, however. These change will inevitably affect our ability to reliably execute the project ourselves over time, but it is surely more pronounced when we expect our project to run on a different machine! To address these elements of the computing environment, we need another, more computing-comprehensive tool.
A powerful and popular approach to reproducible software and operating system, as well as hardware environments, is to use Docker. Docker is software that provides a way to create and manage entire computing environments. These environments are called containers, and they are portable, consistent, and almost entirely isolated from the host system they run on. This means that a container can be run on any machine that has Docker installed, and it will run the same way regardless of the host system. Containers are widely used as they are quick to develop, easy to share, and allow for the execution of code safely separate from the host system.
Each container is based on an image —a blueprint which includes the operating system, system dependencies, and software. An images is created using a Dockerfile, which is a text file that contains a set of instructions for creating the image. We craft our own Dockerfile and build an image from it or we can take advantage of pre-built images that are available in image registries such as Docker Hub or GitHub Container Registry. Thanks to helpful R community members, there are Docker images built specifically for the R community and distributed as part of the Rocker Project. These images include a variety of R versions and R environment setups (e.g. R, RStudio Server, Shiny Server, etc.). The Rocker Project’s images are built on the open source and freely available Ubuntu operating system, which is based on Linux. In line with our goal to use open and freely accessible formats and software, Ubuntu is a popular choice. Rocker images are widely used and well-maintained, and are a good choice for creating a reproducible computing environment for an R project. If you are just getting started with Docker, I recommend the Rocker Project’s rocker/rstudio image. This image includes R, RStudio Server, which can be accessed through a web browser, and other key software. It also provides support for multiple computing architectures (e.g. AMD, ARM, etc.).
Once the research compendium is prepared and a strategy for the computing environment identified, the project can be published. If you are using a version control system, such as Git, to manage your project, you will likely want to publish the project to a remote repository. This makes your project accessible to others and provides a means to collaborate with other researchers. GitHub is a popular platform for publishing coding projects and it provides a number of services in addition to version control that are useful for research projects, including issue tracking, website hosting, and continuous integration (CI). CI is a technology which allows for the automatic building, testing, and/or deployment of code changes when they are added to a repository.
There are a few steps to take before publishing a project to a remote repository. First, you will want to ensure that the strategies for reproducing the project are well-documented. This includes describing where to find the Docker image for the project and how to run the project, including how to restore R packages from the renv.lock file. Second, you will want to ensure that you are publishing only the files that are necessary to reproduce the project and for which you have permissions to share.
I want to stress that adding your project to a publicly visible code repository is a form of publication. And when we work with data and datasets we need to consider the ethical implications of sharing data. As part of our project preparation we will have considered the data sources we used and the data we collected, including the licensing and privacy considerations. The steps outlined in Chapter 5 to 7 will either gather data from other sources or modify these sources which we add to our data/ directory. If we do not have permissions to share the data included in this directory, or sub-directories, we should not share it on our remote repository. To avoid sharing sensitive data, we can use a .gitignore file to exclude the data from the repository. This file is a text file that contains a list of paths to files and directories that should be ignored by Git. This file can be added to the project directory and committed to the repository.
Since we have explicitly built in mechanisms in our project structure to ensure that the processing code is modular and that it does not depend on input or previous states, a researcher can easily recreate this data by executing our project. In this way, we do not share the data, but rather we share the means to recreate the data. This is a good practice for sharing data and is a form of reproducibility.
With your project published to a remote repository, you can connect it to other venues that list research projects, such as Open Science Framework, Zenodo, and Figshare. These platforms enhance the visibility of your project and provide a means to collaborate with other researchers. A Digital Object Identifier (DOI) will be assigned to the project which can be used to cite the project in articles and other research outputs.
Website hosting can also be enable with GitHub through GitHub Pages. GitHub Pages is a static site hosting service that takes HTML, CSS, and JavaScript files from a GitHub repository on a given branch and publishes a website. This can be useful for sharing the research project with others, as it provides a means to navigate the project in a web-based environment.
The project structure, computing environment, and publication strategies outlined here are opinionated, but they are also flexible and can be adapted to suit the needs of your research project. The goal, however, should always be the same: to ensure that the computational research project is transparent, well-documented, and reproducible, and that it is accessible to others.
Now, as we wrap up this chapter, and the book, it is an opportune moment to consider the big picture of a reproducible research project. In Figure 11.2, we see the relationship between each stage of the research process, from planning to publication, and their interconnectivity. These efforts reflect our goal to generate insight from data and to communicate that insight to others.
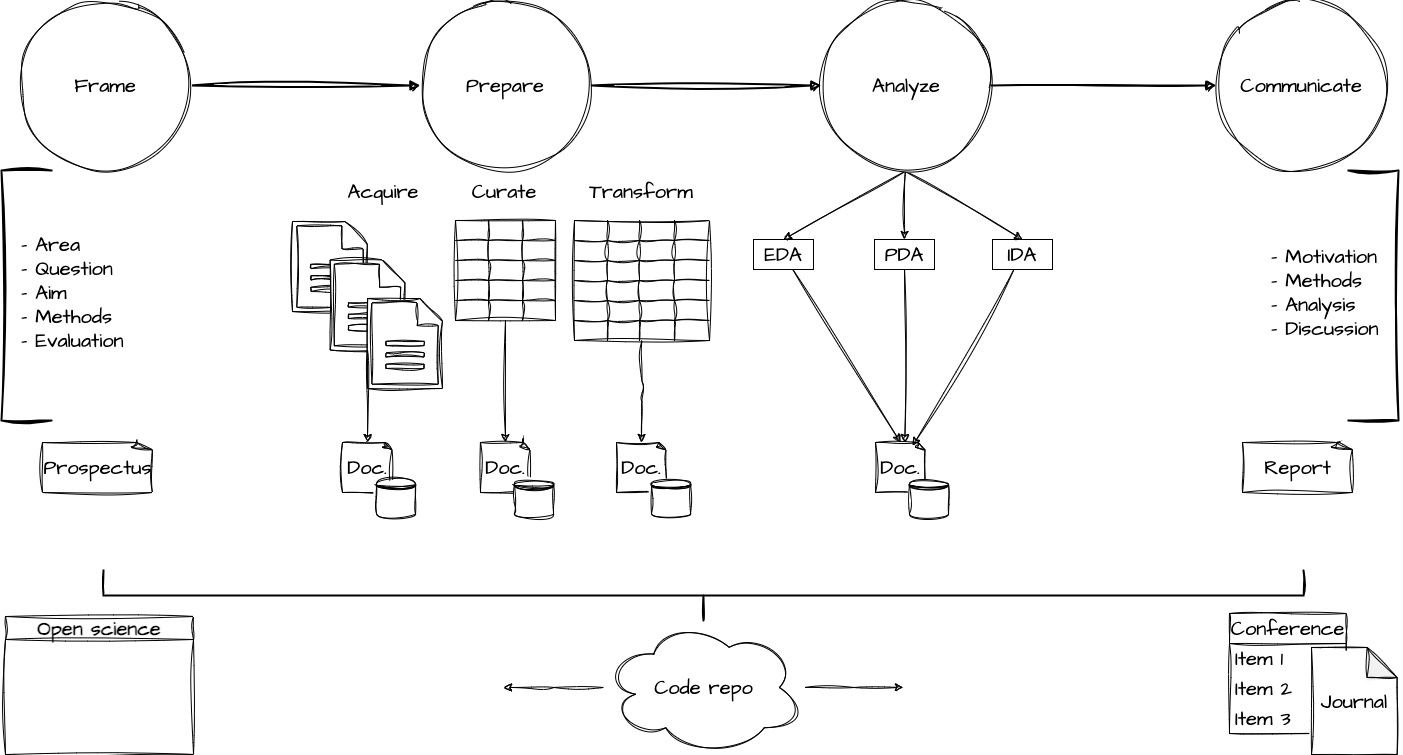
I represent the four main stages in reproducible research: frame, prepare, analyze, and communicate. Each of these stages, and sub-stages are represented as parts and chapters in this book. In Table 11.4, I summarize the stages and sub-stages of a reproducible research project, including the purpose of each stage and sub-stage, the code that is used to execute the stage and sub-stage, and the input and output of each stage and sub-stage.
| Stage | Sub-stage | Purpose | Input | Code | Output |
|---|---|---|---|---|---|
| Frame | Plan | Develop a research plan | Primary literature | - | Prospectus |
| Prepare | Acquire | Gather data | - | Collects data | Original data, data origin file |
| Prepare | Curate | Tidy data | Original data | Create rectangular dataset | Curated dataset, data dictionary file |
| Prepare | Transform | Augment and adjust dataset | Curated dataset | Prepare and/or enrich dataset | Research-aligned data, data dictionary file |
| Analyze | Explore, predict, or infer | Analyze data | Transformed dataset | Apply statistical methods | Key statistical results, tables, visualizations |
| Communicate | Public- and/or Peer-facing | Share research | Analyzed data artifacts | Write-up, publish | Research document(s), computing environment, website |
In conclusion, the goal of research is to develop and refine ideas and hypotheses, sharing them with others, and to build on the work of others. The research process outlined here aims to improve the transparency, reliability, and accessibility of research, and to enhance the visibility and impact of research. These goals are not exclusive to text analysis, nor linguistics, nor any other field for that matter, but are fundamental to conducting modern scientific inquiry. I hope that the strategies and tools outlined in this book will help you to achieve these goals in your research projects.
Activities
The following activities are designed to dive deeper into the process of managing a research project and computing environment to ensure that your research project is reproducible.
Summary
In this chapter, we have discussed the importance of clear and effective communication in research reporting, and the strategies for ensuring that your research project is reproducible. We have discussed the role of public-facing research including presentations and articles. We also emphasized the importance of well-documented and reproducible research in modern scientific inquiry and outlined strategies for ensuring your research project is reproducible. As modern research practice continues to evolve, the details may change, but the principles of transparency, reliability, and accessibility will remain fundamental to conducting modern scientific inquiry.